

KafkaSource는 스파크의 Structured Streaming에서 Apache kafka를 data source로 사용하기 위한 목적이다. 이 library의 source는 아래에서 확인할 수 있다.
Spark Kafkasource : https://github.com/apache/spark/blob/master/external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaSource.scala
2개의 핵심 function을 아래와 같이 정리할 수 있다.
- getOffset() : KafkaOffsetrReader를 사용하여 가장 최근의 offset을 가져온다.
- getBatch() : offset의 처음부터 끝까지에 존재하는 DataFrame을 가져온다.
만약 spark-sql-kafka-0-10 패키지를 사용한다면 아래와 같이 명시적으로 package사용함을 명시해야한다.
./bin/spark-shell --packages org.apache.spark:spark-sql-kafka-0-10_2.12:2.4.3위 숫자들은 각각의 버젼을 뜻한다.
1) 0-10 : kafka version
2) 2.12 : scala version
3) 2.4.3 : Spark version
Kafka Source Provider 코드
KafkaSrouceProvider는 아래와 같은 옵션이 필수로 들어간다.
- subscribe, subscribepattern, or assign
- kafka.bootstrap.server
위 옵션을 사용하여 만든 기본코드는 아래와 같다.
kafka_df = spark.readStream.\
format("kafka").\ # set data ingestion format as Kafka
option("subscribe", "<topic_name>").\ #This is required although it says option.
option("kafka.bootstrap.servers", "localhost:9092").\ #You will also need the url and port of the bootstrap server
load()
만약 data의 schema를 확인하고 싶다면 아래와 같은 코드를 사용하면 된다.
import logging
from pyspark.sql import SparkSession
def run_spark_job(spark):
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:<your port>") \
.option("subscribe", "<your topic name>") \
.option("startingOffsets", "earliest") \
.option("maxOffsetsPerTrigger", 10) \
.option("stopGracefullyOnShutdown", "true") \
.load()
# Show schema for the incoming resources for checks
df.printSchema()
if __name__ == "__main__":
logger = logging.getLogger(__name__)
spark = SparkSession \
.builder \
.master("local[*]") \
.appName("StructuredStreamingSetup") \
.getOrCreate()
logger.info("Spark started")
run_spark_job(spark)
spark.stop()- startingOffsets : 읽어올 offset의 시작위치 설정
- maxOffsetsPerTrigger : trigger interval per offset
- stopGracefullyOnShutdown : true로 할경우 StreamingContext를 바로 shutdown하지 않고 JVM절차에 따라 shutdown한다(default false)
Kafka Offset Reader
KafkaOffsetReader class는 Spark에서 Kafka의 offset을 읽어오는 역할을 한다. 이 class는 ConsumerStrategy class를 사용하는데, 어느 topic, partition에서 읽어올지 정의한다.

만약 WAL(Write Ahead Log)를 통해 고가용성을 유지하고 싶다면 아래와 같은 방식을 사용하면된다.
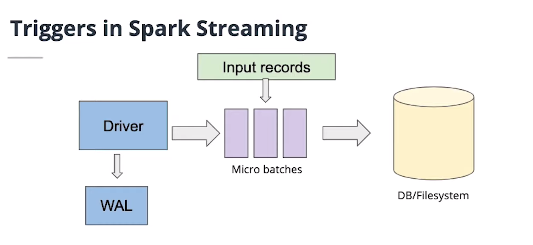
spark.streaming.receiver.writeAheadLog.enable
'빅데이터 > Kafka' 카테고리의 다른 글
| 카프카 장애대응 - Consumer offset 지정하기(by partition) (2) | 2020.01.31 |
|---|---|
| Kafka burrow 모니터링 하지 않는 consumer group 수동제거방법 (0) | 2020.01.15 |
| Kafka | MirrorMaker2 가 release되었습니다. (0) | 2019.12.18 |
| 카프카를 쿠버네티스 위에 올리는게 좋은 선택일까? (1) | 2019.11.07 |
| 아파치 카프카 Lag 모니터링 대시보드 만들기 (3) | 2019.11.01 |
| Kafka client 2.0 부터 KafkaConsumer.poll(long)은 deprecated됩니다. (1) | 2019.10.22 |