
아래 포스트는 confluent 블로그 글을 토대로 제 의견과 함께 정리한 글입니다.
위 블로그글은 Gwen Shapira(하둡 애플리케이션 아키텍처, 카프카핵심가이드 저자이자 confluent PM)이 작성한 글입니다.
쿠버네티스위에 카프카를 올려야하나?
쿠버네티스를 사용하는 주요 이유 2가지는 아래와 같습니다.
- 개발자와 운영자 모두에게 workflow의 효율을 높임으로서 생산성이 높아짐
- "bin packing(1개 가상/물리 장비에서 여러 application을 돌리는 것)"을 통해 리소스 관리 효율화 가능
그런데, 카프카는 운영하기 그렇게 어렵지 않으며, 가끔 node(가상/물리 장비)의 모든 resource를 필요할때가 있습니다. 그렇기 때문에 쿠버네티스 위에서 카프카를 운영하는 것은 그닥 장점이 많지는 않습니다.
그럼에도 불구하고 카프카를 쿠버네티스위에 올려야 한다면? 이유는?
만약 쿠버네티스를 적극적으로 사용하면서 마이크로서비스 아키텍쳐로 여러 애플리케이션을 효율적으로 운영하고 있다면 쿠버네티스 위에 카프카를 올리는 일은 그렇게 어렵지는 않을 것입니다. 많은 기업들에서 쿠버네티스에 카프카를 올리는 이유중 하나는 많은 승인과정때문이라고 합니다. 쿠버네티스 위에 올림으로서 기존 내부 조직(네트워크팀 등)과 싸우지 않고, 여러 환경설정(네트워크 등)을 빠르게 할당할 수 있으며 빠르게 상용환경에 배포할 수 있습니다.
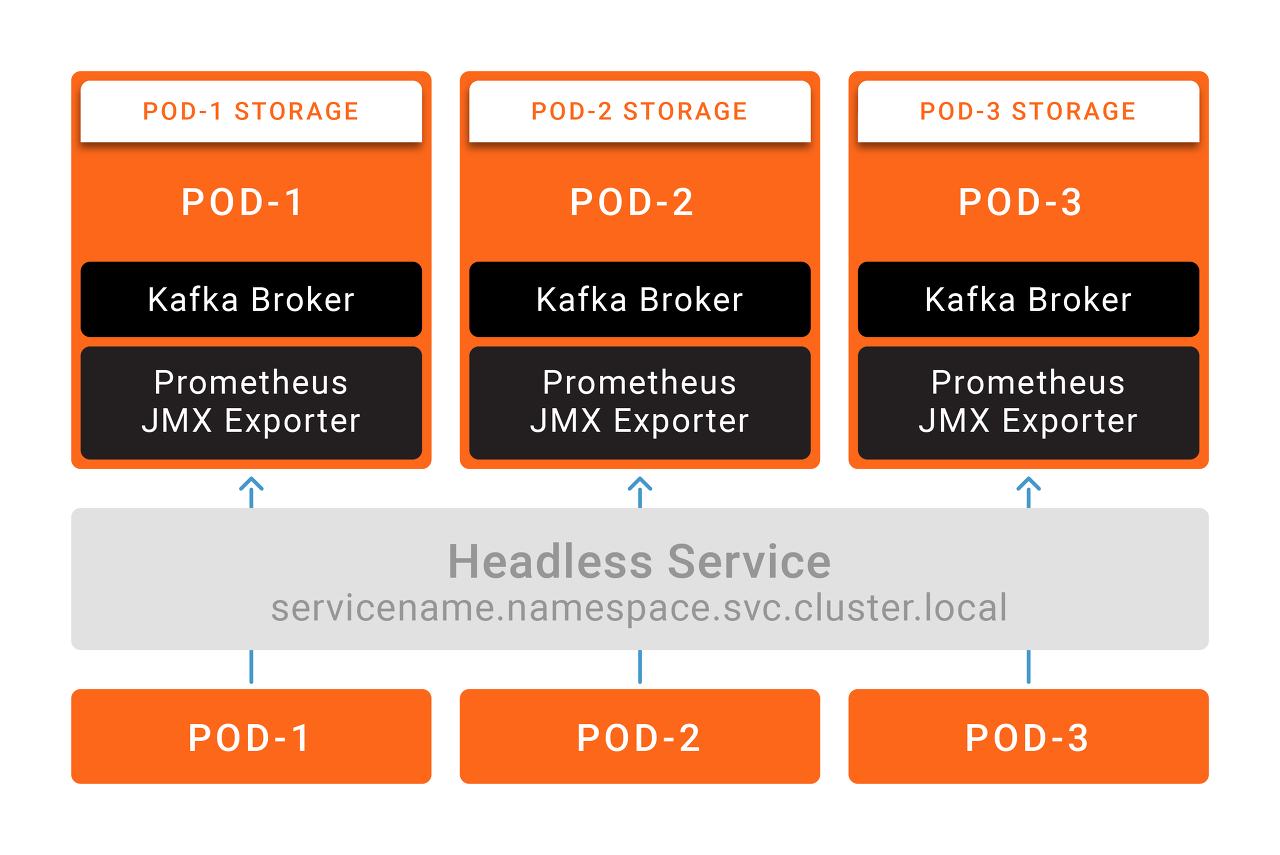
그리고 많은 기업에서는 카프카 클러스터를 구축할때 과소평가하곤 합니다. use case가 많아질수록 카프카 broker의 개수는 더욱더 늘어나게 되는데, 이때 Confluent Opreator을 사용한다면 카프카 클러스터를 더욱 쉽게 배포하고 관리 할 수 있습니다.(Gwen Shapira 의견) 쿠버네티스에서 카프카를 운영함으로서 한줄의 command 혹은 한줄의 configuration line으로 더욱 쉽게 scale up(add new broker 등) 할 수 있습니다. 또한 카프카 크러스터의 업그레이드나 재시작도 더욱 쉽게 가능합니다.
하지만 카프카를 쿠버네티스에 올리는 것은 생각보다 어렵다.
카프카는 stateful 서비스이고 stateful 서비스 운영을 위한 POD을 올린다면 쿠버네티스에서는 stateless 서비스보다 다소 복잡한 설정을 해야합니다. 가장 어려운점은 저장소(storage)와 네트워크 그리고 지연(latency)에 대한 설정입니다.
카프카를 쿠버네티스 위에 stateful 서비스로 올리기 위해서는 쿠버네티스의 shared storage가 필요합니다. 쿠버네티스(1.8.x)에서는 local persistent storage를 지원하긴 하지만 아직 beta이고 상용환경에 적용하는 것은 권장되지 않기 때문에 shared storage를 사용합니다. 안타깝게도 많은 기업에서는 shared storage device를 사용할 시에 낮은 지연을 보장하기 어렵습니다. 쿠버네티스 위에 카프카를 성공적으로 운영하기 위해서는 저장소 팀(storage team, infra팀)과 이런 쿠버네티스 저장소에 대한 요구사항에 대해 함께 파악해야하며 검증해야합니다.
카프카는 stateful 서비스로 운영되며 브로커는 교체되지 않으면서도 client들은 브로커와 직접적으로 통신합니다. 그러므로 카프카 클러스터는 일반적인 웹서비스처럼 single load balancer address로 사용할 수는 없습니다. 쿠버네티스에서 카프카 클러스터를 구성할때는 각 브로커마다 각각 네트워크를 따로 설정해주어야 한다는 것입니다. 이것은 그렇게 어렵지는 않지만 이 또한 많은 부분에서 네트워크 팀(network team, infra팀)과 소통하여 검증하는 것이 필요합니다.
위 2가지 사례 저장소, 네트워크를 구성하는데 어려움 뿐만아니라 추가적으로 kafka cluster metric을 모니터링 하기위한 JMX exporter설정이나 kafka broker log 수집을 위해 추가적으로 sidecar pod을 구성하는 것을 고려해야 합니다.
결론
만약 Helm Chart와 confluent operator를 사용함과 동시에 저장소팀, 네트워키 팀과 협업을 잘 한다는 가정이 있다면, 쿠버네티스 위에 카프카를 올리는 것은 생각보다 쉽습니다. 그러나, 카프카를 효과적으로 운영하기 위해서는 많은 요구사항들(broker log처리, broker metirc수집, zookeeper 구성, 속도 등)을 생각해야합니다. 요구사항을 효율적으로 해결하기 위해서는 쿠버네티스에 대한 지식은 당연히 알아야할 뿐만 아니라 카프카에 대해서도 어떻게 운영해야할지 명확히 알고 있어야 합니다. 그렇기 때문에 만약 쿠버네티스에 대한 운영노하우 또는 카프카에 대한 운영노하우 둘 중 하나라도 미흡하다면 쿠버네티스 위에 카프카를 올려서 운영하는 것은 아주 어려운일이라고 생각합니다.
만약 쿠버네티스를 운영하는데 노하우가 충분히 있으면서 쿠버네티스 클러스터를 운영하는 팀 그리고 저장소, 네트워크팀의 효과적인 소통을 기대할 수 있다면 쿠버네티스 위에 카프카를 구성하여 운영하는 것은 좋은 선택으로 볼 수 있습니다.
그러므로 현재 조직, 팀에 주어진 요구사항과 환경에 대해 확인하여 쿠버네티스 위에 카프카를 올려서 운영할지 결정하면 될것입니다.
'빅데이터 > Kafka' 카테고리의 다른 글
| Kafka burrow 모니터링 하지 않는 consumer group 수동제거방법 (0) | 2020.01.15 |
|---|---|
| Kafka | MirrorMaker2 가 release되었습니다. (0) | 2019.12.18 |
| 스파크 스트리밍-Kafka Data source 소개 (0) | 2019.12.03 |
| 아파치 카프카 Lag 모니터링 대시보드 만들기 (3) | 2019.11.01 |
| Kafka client 2.0 부터 KafkaConsumer.poll(long)은 deprecated됩니다. (1) | 2019.10.22 |
| 아파치 카프카 강의 #2 - 토픽이란? 토픽의 기능 소개 (0) | 2019.10.21 |