
아래 포스트는 엔지니어 블로그를 번역하였습니다.
2019년 10월 8일 Linkedin이 엔지니어 블로그를 통해 내부에서 사용중인 kakfa를 공개하였다.
blog : https://engineering.linkedin.com/blog/2019/apache-kafka-trillion-messages
github : https://github.com/linkedin/kafka
아파치 카프카는 링크드인의 인프라에서 중요한 부분을 차지한다. 아파치 카프카는 처음에 in-house 스트림 프로세싱 플랫폼으로 개발하다가 오픈소스로 공개하였고 오늘날에는 많은 적용사례들이 있다. 아파치 카프카는 activity tracking, message exchange, metric gathering과 같은 역할을 하는 소프트웨어 스택을 사용할 때 유용하게 사용된다.
링크드인에서는 100개이상의 카프카 클러스터와 4,000개 이상의 카프카 전용 서버(broker)로 구성되어 있다. 모두 합치면 100,000개 이상의 토픽과 7,000,000개 이상의 파티션으로 구성되어 있다고 보면 된다. 하루 동안 카프카를 통해 처리되는 총 메시량은 7조개가 넘는다.
카프카 에코시스템을 지속적으로 확장시키기 위해 여러 상용 이슈들이 있었다. 해당 이슈들을 해결하기 위해 링크드인에서는 internal release 브랜치를 만들어서 내부 kakfa에 적용시켜 상용환경에서 사용해 왔다.
우리의 이런 내부 release 브랜치들을 Github에 공개하기로 결정하였고, 이 결정에 대해 매우 기쁘게 생각한다. 우리는 이런 브랜치들의 마지막이름에 -li 를 붙여서 분리하였다. 아래에는 왜 이런 내부 브랜치를 따서 운영하게 되었는지에 대한 이야기와 새로운 패치를 운영하는 노하우, 어떻게 운영하고 내부적으로 배포하였는지에 대해 설명하고자 한다.
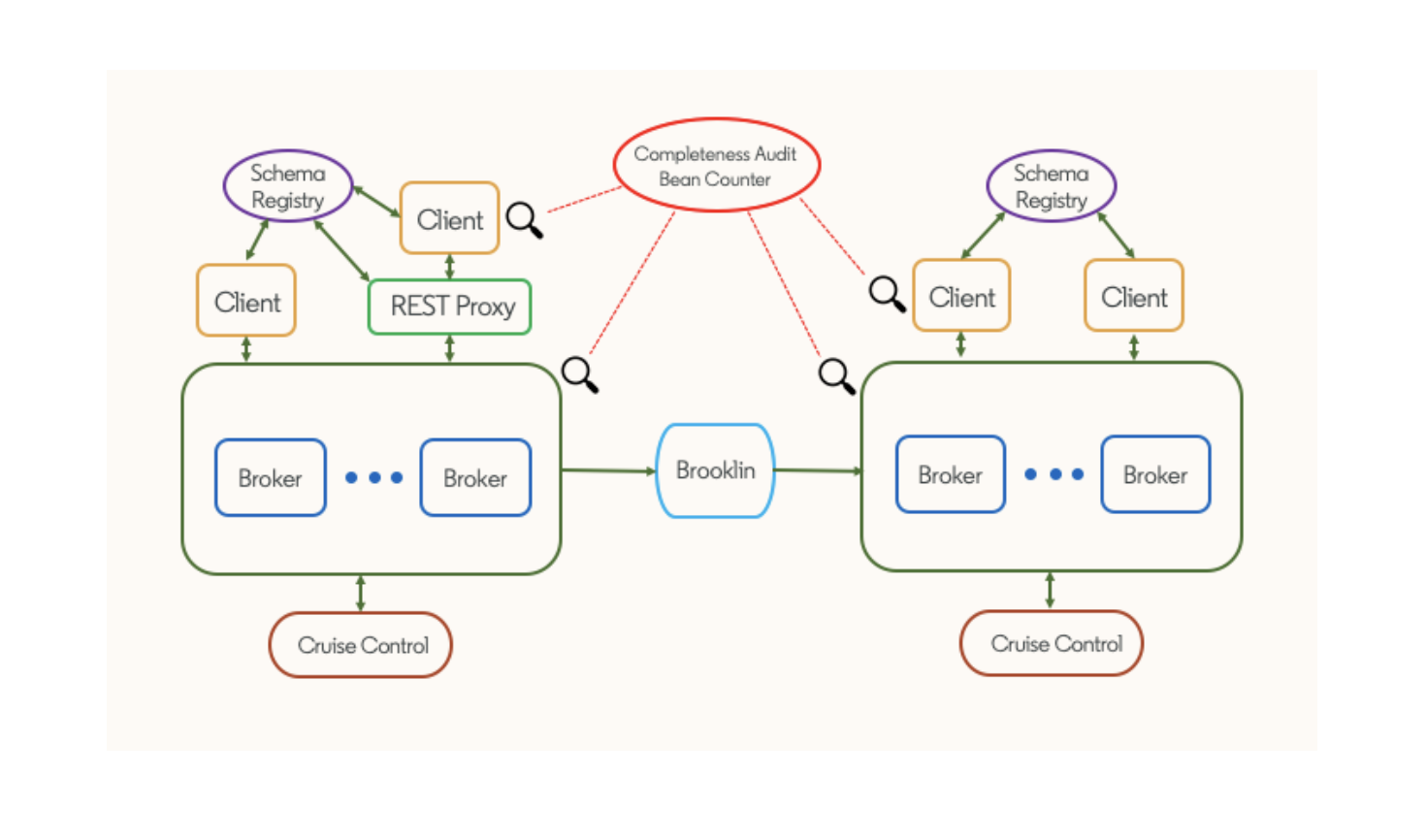
링크드인의 카프카 에코시스템
링크드인에서 카프카는 스트리밍 에코시스템의 핵심기술이다. 카프카 에코시스템은 아래와 같은 구성요소로 이루어져 있다.
- Kafka cluster, brokers
- Kafka clinet applications
- non-Java client를 위한 REST proxy
- Avro 스키마 운영을 위한 스키마 레지스트리
- cluster간에 mirroring을 위한 Brooklin
- 아파치 카프카의 효과적인 운영을 위한 Cruise Control
- 파이프라인 audit, usage 모니터링을 위한 Bean Counter
링크드인 카프카의 릴리즈 브랜치운영
위에서 언급했다싶이 링크드인에서 사용하는 카프카는 내부적으로 브랜치를 생성하여 배포, 운영하고 있다. 링크드인에서 사용중인 내부 카프카 버젼은 오픈소스로 나와 있는 아파치 카프카의 버젼과는 다르므로 이점을 주의해야한다.
링크드인에서 카프카 패치를 사용하기 위한 방법으로 아래 2가지 방법을 사용한다.
1) Upstream First
- Kafka Improvement Proposal(KIP)에 수정사항을 적용한다.
- 해당 수정사항을 링크드인내부 릴리즈 브랜치에 저굥ㅇ한다.
2) LinkedIn first(핫픽스일 경우)
- 링크드인 내부 브랜치에 수정사항을 적용한다.
아래 브랜치 그림을 보면 위에서 설명한 링크드인 내부 브랜치의 운영에 대한 flow를 더 자세히 확인할 수 있다.

무엇을 내부 브랜치에 적용했는가?
링크드인 내부에서 어던 사유로 어떤 수정사항을 패치했는지 이야기 해보고자한다.
1) Scalability improvements
링크드인에서 어떤 카프카 클러스터는 140개 이상의 broker로 운영되고 있으며 single cluster에 백만개의 replica가 존재하는 경우도 있다. 이렇게 큰 클러스터의 경우 memory의 한계로 인해 Kafka controller의 이슈(slow, failure)가 있었다. 이 이슈들은 운영환경에서 아주 큰 문제로 작용하였다. 우리는 Kafka controller의 memory를 적게 사용하는 방안으로서 UpdateMetadataRequest object를 재사용 하는 방식으로 내부동작을 수정하여 hotfix로 적용하였다.
그리고, 많은 개수의 브로커로 이루어진 클러스터를 운영할 때 브로커를 shutdown/startup시에 아주 느려짐을 확인하였다. 이런 배포이슈에 대해서서 브로커의 shutdown/startup시간을 줄이기 위해 hotfix를 적용하기도 했다. (e.g, a patch to improve shutdown time by reducing lock contention).
2) Operational Improvements
카프카를 운영함에 있어 이슈가 있어 적용하는 경우도 있었다. 예를 들어 SRE개발자가 카프카 클러스터의 상태가 나쁜 브로커를 자주 없애고 신규 브로커를 넣을 때가 있었다. 이 때 브로커가 클러스터에서 빠질 경우 data loss가 일어나는 것을 막아야 했다. 이를 해결 하기 위해 SRE개발자는 해당 브로커에 레플리카 데이터를 모두 빼야했지만 이는 매우 어려운 작업이였다. 그래서 broker에 운영모드(maintenance mode)라는 것을 새로개발하였다.
브로커가 운영모드로 변환할 경우 더이상 새로운 토픽의 파티션과 레플리카가 브로커에 할당(assign)되지 않는다. 이를 통해 모든 레플리카는 다른 broker로 옮겨가게 되며 data loss없이 브로커를 깔끔하게 클러스터에서 뺄 수 있게 되었다.
3) New features and direct contribution to upstream
그 외에도 여러 다른 기능들을 오픈소스로 나와 있는 아파치 카프카에 기여하기도 했다.
- KIP-219: Improve quota communication
- KIP-380: Detect outdated control requests and bounced brokers using broker generation
- KIP-291: Separating controller connections and requests from the data plane
- KIP-354: Add a Maximum Log Compaction Lag
결론
이번 포스트에서 링크드인이 내부 카프카를 효과적으로 운영하기위해 어떻게 customize했는지에 대해 살펴보았다. 링크드인에서 내부적으로 수정사항이 있을 경우 나중에 외부 공개가 가능하게 끔 공들여 수정하여 패치하였다. 이번 링크드인 내부 카프카로 공개한 opensource는 기여받지는 않을 예정이다. 그러나 이 글을 읽고 있는 분 중에 기여(contribute)를 하고 싶다면 현재 오픈소스로 나와 있는 아파치 카프카에 패치하는것을 권장한다.
'빅데이터 > Kafka' 카테고리의 다른 글
| 아파치 카프카 강의 #1 - 소개 및 개요 (4) | 2019.10.21 |
|---|---|
| KSQL 소개 ppt (0) | 2019.10.16 |
| KSQL에러 extraneous input 'properties' expecting (0) | 2019.10.16 |
| Airbnb에서 Kafka의 활용 (0) | 2019.10.14 |
| Kafka의 KSQL 컨셉, 아키텍쳐, 용어, 커스텀 function 적용하는 방법 (0) | 2019.10.11 |
| 아파치 카프카 테스트용 data generator 소개 - ksql-datagen (0) | 2019.10.10 |