
KSQL은 스트리밍 application을 SQL 쿼리를 사용하여 만들 수 있다.
KSQL은 Kafka stream으로 만들어져 있다. KSQL은 Kafka 클러스터와 연동되는데 이는 기본적인 Kafka stream application동작구조와 동일하다.
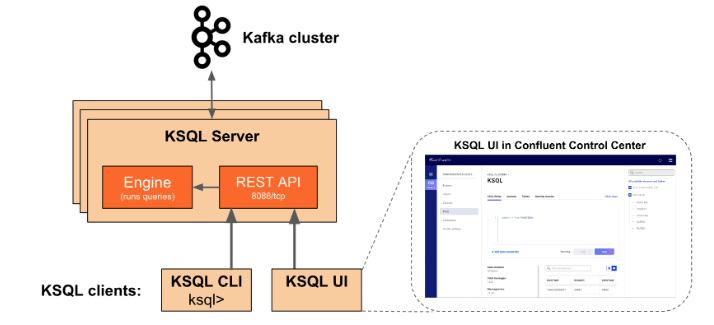
KSQL 아키텍쳐와 주변 application들
KSQL은 아래와 같은 구성요소로 이루어져 있다.
KSQL 아키텍쳐
- KSQL 엔진 : KSQL 쿼리가 실행되고 있는 곳
- REST 인터페이스 : ksql 엔진에 client로 access할 수 있는 인터페이스
주변 application
- KSQL CLI : KSQL 엔진에 CLI(Command Line Interface)로 접속할 수 있게 도와주는 application
- KSQL UI : Confluent Control Center를 사용하여 KSQL을 접근가능하게 도와줌
KSQL서버는 KSQL엔진, REST인터페이스로 이루어져 있다. KSQL서버는 Kafka 클러스터와 통신을 하게 도와준다.
KSQL 엔진
KSQL엔진은 KSQL쿼리를 실행시킨다. KSQL 쿼리를 작성하고 실행하면 KSQL서버안에서 application을 build하고 실행시킨다. 각 KSQL서버들은 KSQL 엔진을 인스턴스로 실행시킨다.
KSQL CLI
KSQL CLI는 console화면에서 KSQL 엔진에 접근할 수 있도록 도와준다. KSQL CLI는 KSQL 서버인스턴스와 연동되며 streaming application을 개발하는데 사용할 수 있다. KSQL CLI는 Mysql이나 Postgre와 같은 cli와 유사한 모습으로 사용가능하다.
REST 인터페이스
Rest서버는 KSQL엔진과 통신하면서 CLI나 Confluent Control Center 혹은 기타 application과 rest통신을 할 때 사용된다.
KSQL과 Kafka스트림과의 관계
KSQL은 Kafka 스트림으로 만들어져 있다. Robust stream processing framework로서 사용할수 있다. Kafka를 사용하면서 KSQL과 Kafka 스트림을 동시에 사용할 수도 있다. 만약, KSQL application에 사용자의 커스텀 function을 넣고 싶다면 아래와 같은 방법으로 추가 가능하다.
KSQL 커스텀 function개발(UDF, UDAF)
kSQL은 스트리밍데이터를 처리하는데 있어 기본적으로 많은 함수들을 제공한다. ABS, SUM과 같은 함수를 예로 들 수 있다. 이러한 함수들은 KSQL query로 사용되어 데이터들을 filter, transform, aggregate 하는데 유용하게 사용할 수 있다.
KSQL API를 사용하여 사용자는 커스텀 function들을 개발 하여 추가할 수 있다. 예를 들자면 이미 정의된 machine learning model을 function으로 추가할 수도 있다.
KSQL은 2가지 방식의 함수를 지원한다.
Stateless scalar function(UDF)
User-Defined Function(UDF)라고 불리는 scalar function은 1개의 row를 intput으로 받으면 1개의 데이터를 output으로 return받을 수 있다.
UDF로 작성한 곱하기 function class의 예시코드
import io.confluent.ksql.function.udf.Udf;
import io.confluent.ksql.function.udf.UdfDescription;
@UdfDescription(name = "multiply", description = "multiplies 2 numbers")
public class Multiply {
@Udf(description = "multiply two non-nullable INTs.")
public long multiply(
@UdfParameter(value = "V1", description = "the first value") final int v1,
@UdfParameter(value = "V2", description = "the second value") final int v2) {
return v1 * v2;
}
}
Stateful aggregate function(UDAF)
User-Defined Aggregate Function(UDAF)라고 불리는 aggregate function은 N개의 row를 input으로 받아서 1개의 데이터를 output으로 받을 수 있다.
UDAF로 작성한 long value들을 더하기 하는 function class의 예시코드
@UdafDescription(name = "my_sum", description = "sums")
public class SumUdaf {
@UdafFactory(description = "sums longs")
// Can be used with table aggregations
public static TableUdaf<Long, Long> createSumLong() {
return new TableUdaf<Long, Long>() {
@Override
public Long undo(final Long valueToUndo, final Long aggregateValue) {
return aggregateValue - valueToUndo;
}
@Override
public Long initialize() {
return 0L;
}
@Override
public Long aggregate(final Long value, final Long aggregate) {
return aggregate + value;
}
@Override
public Long merge(final Long aggOne, final Long aggTwo) {
return aggOne + aggTwo;
}
};
}
}
KSQL 커스텀 function을 적용하는 순서
1. UDF 혹은 UDAF를 만들기 위해서는 Java로 class를 작성해야 한다.
- UDF로 Java class를 작성하려면 @UdfDescription과 @Udf 어노테이션을 사용한다.
- UDAF로 Java class를 작성하려면 @UdafDescription과 @UdafFactory 어노테이션을 사용한다.
2. Jar 파일을 KSQL extension 디렉토리에 배포한다.
- 배포하는방법은 여기(링크)에서 확인 할 수 있다.
3. KSQL function으로 커스텀 function들을 사용한다.
KSQL 쿼리 사용방법
여타 관계형 데이터베이스처럼 KSQL은 2개의 statement를 지원한다. 하나는 DDL(Data Definition Laguage)이고, 다른 하나는 Data Manipulation Language(DML)이다. 이 2개의 statement는 비슷한 syntax, 데이터타입, 표현식을 가지지만, 조금 다르게 동작한다.
DDL statement
KSQL서버에서 stream과 table을 추가, 변경, 삭제하기 위해서 반드시 필요하다. KSQL의 DDL statement들은 아래와 같다.
- CREATE STREAM
- CREATE TABLE
- DROP STREAM
- DROP TABLE
- CREATE STREAM AS SELECT(CSAS)
- CREATE TABLE AS SELECT(CTAS)
DML statement
KSQL 스트림과 테이블에서 data를 읽거나 수정할 때 사용할 수 있다. KSQL엔진은 DML statement를 컴파일해서 Kafka stream appliation으로 만들어 실행된다. KSQL의 DML statement들은 아래와 같다.
- SELECT
- INSERT INTO
- CREATE STREAM AS SELECT(CSAS)
- CREATE TABLE AS SELECT(CTAS)
KSQL query의 특징
KSQL은 SQL과 아주 유사한 특징을 가지고 있다.
- KSQL statement는 semicolon(;)으로 종료된다.
- String문자열은 1개 또는 2개의 따옴표('')로 묶어 사용한다.
KSQL 주요 용어 설명
STREAM
Stream은 구조화된 데이터(structured data)의 연속된 데이터를 뜻한다. 예를 들자면 '철수가 영희에게 100원을 전송하고, 길동이가 민희에게 1000원을 전송'하는 것과 같은 금융 트랜젝션 데이터 스트림이 있다. Stream 데이터는 변하지 않는다(immutable). 즉, Stream 데이터는 계속해서 추가(insert)가능하지만 절대로 update되거나 delete되지 않는다는 것이다. Stream데이터는 Kafka topic으로 부터 혹은 이미 존재하는 stream으로부터 파생하여 만들 수 있다. Stream으로 만든 데이터는 Kafka topic으로 저장된다.
TABLE
Table은 Stream 혹은 다른 table을 조회할 수 있다. 예를 들자면 '철수의 현재 잔고는 10원이다'라는 것과 같은 정보를 확인 할 수 있다. 이것은 전통적인 데이터베이스의 테이블과 거의 동일하지만 stream 혹은 windowing을 통해 더 효과적인 데이터를 얻을 수 있다. Table은 변화가능(mutable)하다. 변화가능하다는 뜻은 데이터를 업데이트하거나 삭제할 수 있다는 뜻이다. Table은 Kafka topic 혹은 이미 존재하는 stream, table로 부터 파생하여 만들 수 있다. 이 또한 Kafka topic으로서 table 데이터가 저장된다.
STRUCT
KSQL을 5.0보다 높은 버젼을 사용하면 Avro 혹은 JSON 포맷의 데이터를 STRUCT type으로 Stream이나 Table로 생성 할 수 있다. 아래와 같이 STRUCT type을 사용할 수 있다.
- CREATE STREAM/TABLE (from a topic)
- CREATE STREAM/TABLE AS SELECT (from existing streams/tables)
- SELECT (non-persistent query)
KSQL 배포 및 운영 방법
KSQL steaming application을 배포하고 운영하는 방식으로는 2가지를 선택하여 사용할 수 있다.
- Interative : 데이터 확인 및 파이프라인 개발환경
- Headless : 지속적으로 운영하는 운영 환경
Interactive 배포
Interactive 모드는 KSQL application을 개발할 때 사용할 수 있다. KSQL서버를 interactive모드로 사용시, REST 인터페이스를 통해 CLI나 Confluent Control Center을 사용 할 수 있다.

Interactive모드에서 할 수 있는 것은 아래와 같다.
- 즉시 statement와 query를 작성하여 실행 할 수 있다.
- 서버를 몇십개든 실행시킬 수 있다.
- KSQL server로 CLI나 REST client로 붙어서 사용할 수 있다.
Headless 배포
Headless 모드는 상용환경에서 KSQL application을 배포하기 위해 사용된다. Headless모드 사용시, REST interface는 사용 불가하다. KSQL서버는 오직 SQL file만을 사용하여 동작한다. SQL file은 사용자가 작성한 KSQL statement와 query를 포함하고 있다. Headless 모드는 ETL application 배포에 적합하다.

Headless모드에서 할 수 있는 것은 아래와 같다.
- KSQL서버를 몇개든 생성 할 수 있다.
- KSQL statement를 실행하기 위해 SQL file을 배포해야한다.
- Query의 변경에 대한 version-control이 가능하다.
- KSQL 쿼리별로 리소스 분리가 가능하다.
- Kubernetes와 같이 별개의 system으로 resource관리가 가능하다.
'빅데이터 > Kafka' 카테고리의 다른 글
| KSQL에러 extraneous input 'properties' expecting (0) | 2019.10.16 |
|---|---|
| 링크드인에서 사용중인 커스텀 Kafka 공개 (1) | 2019.10.15 |
| Airbnb에서 Kafka의 활용 (0) | 2019.10.14 |
| 아파치 카프카 테스트용 data generator 소개 - ksql-datagen (0) | 2019.10.10 |
| KSQL - Docker을 사용한 KSQL server, cli 설치 및 실행 (0) | 2019.10.08 |
| [빅데이터]Kafka stream과 KSQL 소개 및 설명, 차이점 (3) | 2019.10.08 |