

S3는 Simple Storage Service의 약자로 AWS의 강력한 object storage이다.
요구사항에 따라 Java code를 사용하여 aws s3에 file을 write해야할 때가 있다. aws-java-sdk를 사용해도 되지만 apache hadoop에서 제공하는 hadoop-aws를 사용하여 간단하게 file write가 가능하다.
단계 1) 디펜던시 추가
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-aws</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-io</artifactId>
<version>${commons-io.version}</version>
</dependency>
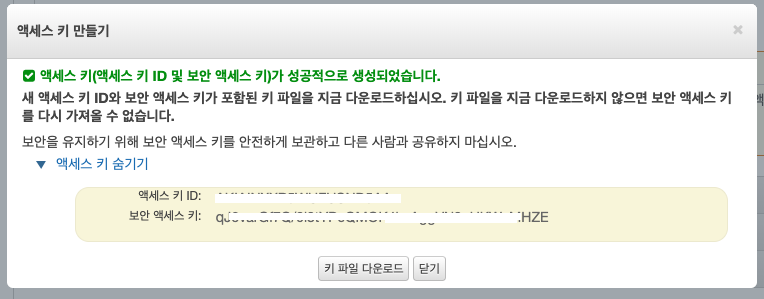
</dependencies>단계 2) AWS에서 secretawsAccessKeyId, awsSecretAccessKey 발급


단계 3) 코딩
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class Main {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.default.name", "s3n://버킷이름");
conf.set("fs.s3n.awsAccessKeyId", "AKIAJWFKNFXXXXXXXX");
conf.set("fs.s3n.awsSecretAccessKey", "xLI7y18tTXXXXXXXXnCfWXXXXXXXX");
FileSystem dfs = FileSystem.get(conf);
Path filenamePath = new Path("/tmp/test/test.log");
FSDataOutputStream out = dfs.create(filenamePath);
out.writeUTF("Hello, world!\n");
out.close();
FSDataInputStream in = dfs.open(filenamePath);
String messageIn = in.readUTF();
System.out.print(messageIn);
in.close();
dfs.close();
}
}
데이터 확인

amazon s3에 계정으로 들어가서 버킷에 들어가보면 지정된 경로에 정상적으로 데이터가 저장된 모습을 볼 수 있다.
'빅데이터 > 하둡' 카테고리의 다른 글
| HDFS cilent 사용시 HA구성된 node 연결하기 (0) | 2020.03.11 |
|---|---|
| pyspark에서 gzip으로 압축되어 있는 파일 읽는 방법 (0) | 2020.02.11 |
| pyspark에러 ImportError: No module named XXXX (1) | 2020.02.10 |
| [local hadoop]localhost port 22: Connection refused 에러 발생시 해결방법 in MacOS (0) | 2020.01.16 |
| Hadoop에서 hadoop job은 어떻게 각 data node에서 job을 수행할까? (0) | 2018.12.17 |
| Hdfs dfs 명령어 정리 및 설명(ls, cat, du, count, copyFromLocal 등) (0) | 2018.12.11 |