
confluent developer certification sample :
20200331-Developer_Certification_Sample_Questions.pdf
0.21MB

driver토픽의 1번 파티션에서 모든 input을 다루는 데이터. 즉, 프로듀서가 레코드를 보내면 리더 파티션이 존재하는 브로커와 통신을 한다. 그러므로 정답은 1번 파티션의 리더가 위치한 102번 브로커가 정답.

카프카 컨슈머가 range partition assignment 전략일 경우 어떻게 파티션과 컨슈머가 연결될 것인지에 대한 정답을 찾는 것이다. range partition assignment의 경우 consumer의 member id를 사전식(알파벳순)으로 정렬하여 각 토픽의 파티션을 숫자를 기준으로 컨슈머에 할당한다. 그러므로 이 경우 다음과 같이 연동된다.
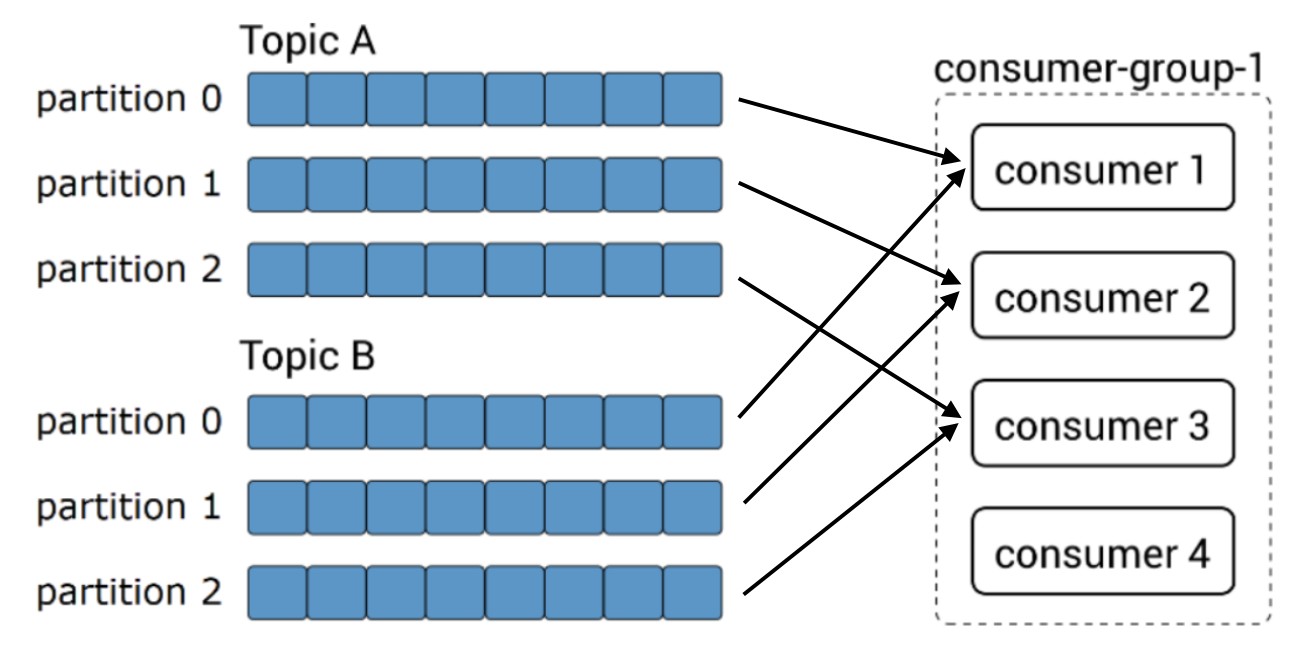
그러므로 정답은 c. 토픽a의 파티션0과 토픽b의 파티션0은 동일 컨슈머에 할당됨.

프로듀서에서 보내는 특정 메시지 키, 메시지 값을 가진 레코드가 특정 토픽의 파티션에 할당되기를 원한다면 어떻게 하면 되는가? 에 대한 질문이다. 디폴트 파티셔너의 경우 메시지 키가 동일하면 동일한 파티션으로 레코드를 전송하므로 별도의 절차나 옵션이 필요 없다.

카프카 클라이언트가 카프카 클러스터로부터 메타데이터를 가져오기 위해 최초로 설정하는 것은 최소 2대 이상의 카프카 브로커의 정보를 입력하여 메타데이터를 가져오는 것이다. 그 이후에 리더 파티션이 존재하는 브로커와 통신한다. 그러므로 정답은 b이다.

최대 한번(at most once) 데이터 전달을 보장하려면 acks=0 또는 acks=1을 설정하면 된다. acks=0의 경우 리더파티션에 저장되지 않을 수 있으므로 데이터가 일부 유실될 수 있고 acks=1로 하는 경우에도 브로커에 이슈가 발생할 경우 일부 데이터가 유실될 가능성이 있다. 리더 파티션에만 적재하고 팔로워 파티션에 적재가 되지 않은 경우가 발생할 수 있기 때문이다.

프로듀서가 최대한 낮은 지연으로 최대의 전송처리를 하고 싶다면 batch.size를 높게하고 linger.ms도 높게하면 최대한 많은 양의 데이터를 모아서 최소한의 네트워크 통신으로 최대량의 데이터를 전송한다.

3대의 브로커가 있고 4대의 프로듀서 클라이언트가 12개의 파티션을 가진 driver토픽으로 데이터를 보낼 때 timeout exception을 최소화하는 방법에 대해 묻고 있다. a의 경우 프로듀서 클라이언트 개수가 많아지므로 오류 경감과 무관하다. driver토픽의 파티션 개수를 늘리는 것도 오류 경감과 무관하므로 b도 정답이 아니다. d와 같이 복제 개수를 늘리는 것도 무관하다. c와 같이 각 브로커마다 12개의 파티션을 각 브로커별 3개 파티션이 위치하도록 하는 것이 가장 최선의 방법일 것이다.(아마 해결이 안될 수도 있지만 경감은 될지도)

상용환경에서 데이터를 전달하는 아키텍처를 짯는데 다음과 같은 결과가 나왔다고 한다. 참고로 연동하는 토픽의 파티션 개수는 20개.
- 5%의 메시지들은 5개 파티션에 데이터가 저장됨
- 20%의 메시지들은 10개 파티션에 데이터가 저장됨
- 75%의 메시지들은 5개의 파티션에 저장됨
- 상용환경에서 원하는대로 메시지들이 전송되었음
즉, 대부분의 메시지가 특정 파티션에 몰리는 경향이 있음을 알 수 있다. 좀 더 메시지가 분산되게 하기 위한 방법은 커스텀 파티셔너(a)를 사용하거나 또는 메시지 키를 다시 지정(c)하는 것이다. 이를 통해 좀더 파티션 카디널리티가 높은 형태로 운영해야할 것이다. 프로듀서 개수를 늘리(b)거나 파티션들을 브로커에 다시 리파티셔닝(d)하는 것은 전혀 상관 없는 이야기이다.

상용환경에서 사용자가 접근하여 보는 데이터와 유저의 프로필 데이터를 병합한 메시지를 만들어내는 방법은 코파티셔닝하는 것이다. 코파티셔닝을 통해 동일한 파티션에 동일한 유저의 정보가 포함되도록 설정할 수 있다. 코파티셔닝이란 파티셔닝 전략을 동일하게 하고 파티션 개수를 동일하게 맞추는 것이다. 이를 통해 카프카 스트림즈 등을 통해 병합 과정을 수행할 수 있다.

온도, 습도와 같은 센서의 데이터와 데이터베이스에 저장된 프로파일 데이터(위치, 모델 등)를 병합하기 위한 좋은 방법을 묻는 문제이다. a의 경우 SMT를 통해 데이터를 묶는다고 했으므로 틀린 문항이다. b의 경우 smt를 통해 데이터를 병합한다고 했으므로 이것도 틀렸다. dㅇ를 보면 직접 소스 데이터베이스에 연동하는것을 예로 들었는데 스트림 데이터처리와 무관하다. c에서는 mqtt 프록시를 사용하여 센서 데이터를 모으고, jdbc source connector를 사용하여 디바이스 프로필을 모은 다음 서로 다른 2개의 토픽을 병합하는 과정을 카프카 스트림즈로 처리하는 것을 언급한다. 스트림 데이터 처리하는데 있어 가장 좋은 방법이므로 c가 정답이다. 가장 올바른 정답 best answer를 정하는 것이므로 d보다는 c가 정답에 가깝다.

카프카 스트림즈 애플리케이션에서 RDBMS의 데이터(고객의 프로필 데이터)가 필요하다고 한다. 가장 좋은 솔루션 방법은 JDBC 소스 커넥터로부터 고객 프로필 데이터를 가져오되 SMT를 통핼 마스킹을 수행하는 것이다. 그리고 카프카 스트림즈를 통해 데이터를 활용하는 것이 베스트 케이스 일것이다. SMT를 사용하면 데이터의 일부 필드를 파싱하여 삭제, 제거, 수정 할 수 있다.

고객의 데이터를 카프카 토픽에 넣는 것이 주요 이슈이다. 이때 데이터 사용량에 따라 가장 알맞게 애플리케이션을 잘 운영하는 방법을 고르라는 문제이다. 카프카 커넥트 워커를 애플리케이션 운영 상황에 따라 스케일 인/아웃 함으로서 리소스를 효과적으로 운영가능할 것이다. b와 같이 task의 개수를 변화하는 것은 리소스 사용량을 최적화하는데 큰 도움이 되지는 않는다.

레거시 RDBMS를 사용할 경우 여러 포맷을 가진 레거시 데이터를 마이크로 서비스에서 운영할 수 있도록 하는것이 요지이다. 개발팀은 SQL을 운영해본 경험이 있고 기존 RDBMS의 SQL문법에 치숙할 경우 가장 좋은 시나리오를 고르는 문제이다. ksqlDB를 활용하면 SQL을 사용하여 스트림 데이터 처리를 수행할 수 있으므로 c가 베스트 케이스이다.
'빅데이터 > Kafka' 카테고리의 다른 글
| 카프카 커넥트의 태스크 밸런싱 로직, DistributedHerder(양치기) 그리고 IncrementalCooperativeAssignor 내부 동작 소개 (0) | 2022.03.23 |
|---|---|
| kafka consumer와 seekToBeginning를 활용하여 offset reset하기 (0) | 2022.01.17 |
| 스키마 레지스트리 자바 클라이언트(프로듀서,컨슈머) 테스트 (0) | 2021.12.16 |
| confluent HdfsSinkConnector 파티셔너 설명 (0) | 2021.11.25 |
| macos에서 podman으로 rest-proxy 실행하기 (0) | 2021.11.16 |
| couchbase 카프카 싱크 커넥트 사용 방법 (0) | 2021.10.29 |