
카프카 스트림즈는 기본적으로 at-least-once 프로세싱을 지원합니다. at-least-once 프로세싱이란 적어도 한번 프로세싱을 지원하는 것으로써 중복은 발생할 수 있고 유실은 절대 발생하지 않는 것입니다. 스트림즈 프로세싱에서라면 특정 레코드에 대해 처리를 하고 유실은 될 수 없고 중복 프로듀스는 될 수 있다는 것입니다.
- at least once : 적어도 한번 처리
- at most once : 많아도 한번만 처리
- exactly once : 딱 한번만 처리
카프카는 0.11.0 이후 버전에서 transaction처리를 지원합니다. 이 옵션을 사용하면 스트림즈 API를 사용할 때 Exactly once 프로세싱을 만족하도록 적용할 수 있습니다. 적용하는 방법은 아래와 같습니다. 코드를 변경할 필요 없이 설정하나만 추가하면 됩니다.
Properties props = new Properties();
props.put(StreamsConfig.PROCESSING_GUARANTEE_CONFIG, "exactly_once"); // default is "at_least_once"스트림 프로세싱에서 왜 exactly once 처리가 어려운지, 그리고 카프카 스트림즈는 어떻게 exactly once 처리를 만족하는지 아래에 정리합니다.
스트림 프로세스에서 Exactly once란?
실시간 스트림 프로세싱 애플리케이션을 만들 때 가장 중요한 것은 '정확성'입니다. 이 정확성이란 추가되는 데이터에 대해 반드시 딱 1번의 아웃풋을 내는지 여부를 뜻합니다. 소프트웨어 엔지니어링에서 데이터의 정확성은 아래와 같은 이유 때문에 영향을 미칠 수 있습니다.
- 코드의 버그
- 설정을 잘못함
- 휴먼 에러
- 기타 등등
스트림 프로세싱에 있어 Exactly-once처리를 한다는 뜻은 각각의 레코드에 대해 처리 중 위에서 언급한 이슈가 발생하더라도 반드시 한번만 처리한다는 것입니다. 아파치 카프카의 스트림즈 처리에 있어 read(consume)-proccess-write(produce)를 한개의 트랜잭션으로 처리한다는 뜻이죠. 한번 읽어들인 레코드는 반드시 한번면 프로듀스 해야 완벽하다고 볼 수 있습니다.
만약 스트림 프로세싱을 하는 애플리케이션을 단 1개 프로세스만 띄워서 처리한다면 exactly once를 달성하는것은 그리 어렵지 않습니다. 그러나 1개 토픽에 대해서 1개 프로세스로 모든 데이터를 처리하는 것은 그 자체로 보틀넥(Bottle-neck)이 되어 더 이상 스케일 아웃하기 어렵게 되죠. 스케일 아웃을 하기 위해서는 반드시 멀티 프로세스로 처리해야만 합니다. 멀티 프로세스에서 Exactly once를 달성하는 것은 엄청나게 어려운 일입니다.
스트림 프로세싱이 잘되었을 때 과정
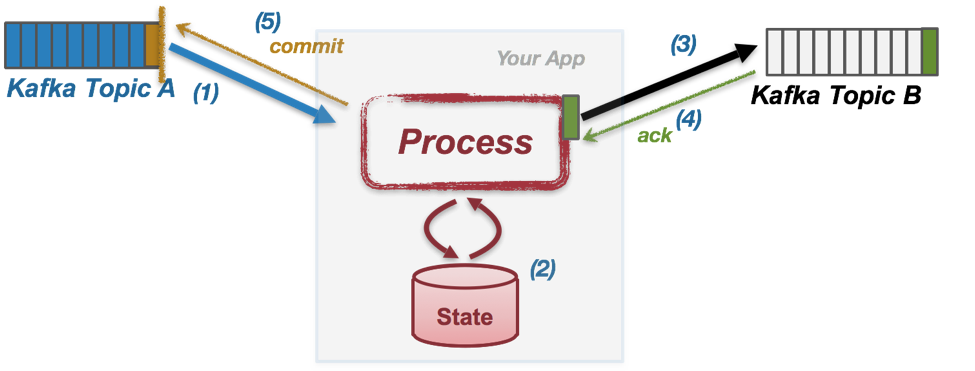
위 5가지 과정은 일반적인 상태기반 데이터 스트림 처리과정을 나타냅니다. 5가지 과정으로 이루어져 있고 각 과정에서 이슈가 발생하지 않는다면 Exactly once 처리를 수행한다고 볼 수 있습니다.
1) 토픽A로부터 데이터를 컨슘
2) 컨슘한 데이터를 상태기반 처리 및 상태 저장
3) 처리 완료된 데이터를 토픽B로 프로듀스
4) 토픽B에 데이터가 정상적으로 저장되었음을 응답(ack) 받음
5) 토픽A에 가져간 데이터가 처리 완료되었음을 응답(commit) 보냄
스트림 프로세싱에서 이슈가 생기는 경우
상기와 같은 5가지 과정에서 이슈가 생겨서 Exactly once를 만족하지 못하는 경우는 크게 두가지가 있습니다.
1. 프로세싱을 완료한 데이터를 2번 쓰는 경우
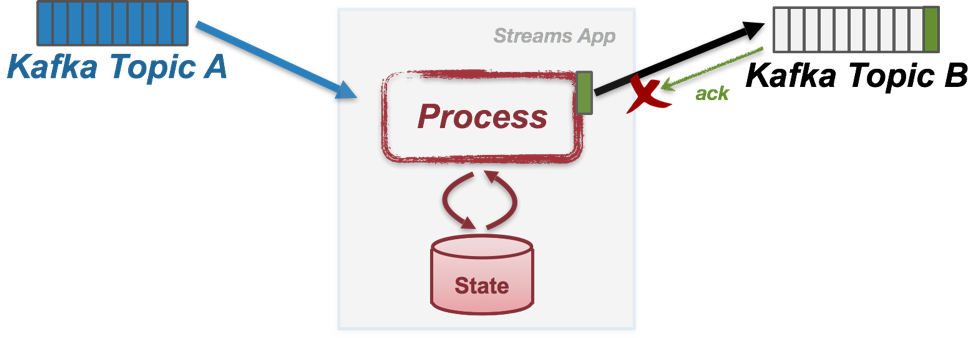
카프카 프로듀스와 브로커간에 네트워크 연결에 이슈가 생겼을 때 흔히 발생하는 현상입니다. 정상적으로 데이터를 보냈으나 ack를 받지 못하는 경우가 있을때 다음과 같이 동일한 데이터가 중복해서 2번 적재될 수 있습니다.

2. 프로세스가 실패할 경우

프로세스가 피치 못하게 종료될 수 있습니다. OutOfMemory나 RunTimeException같은 것들을 예로 들 수 있습니다. 이 경우에는 정상적으로 데이터를 컨슘하고 토픽으로 데이터를 전송하고나서 커밋을 못했을 경우입니다. 커밋을 못하면 데이터를 처리 못했다고 가정하기 때문에 한번 더 데이터를 처리해서 중복이 발생할 수 있습니다.

위의 경우와 같이 중복이 발생하지 않으려면 스트림 처리 과정에서 3가지 과정을 원자성(Atomic)하게 처리해야만 합니다. 카프카 스트림에서는 아래와 같은 3가지가 처리되거나 처리 되지 않아야 합니다.
1. Acked produce to sink topics
2. State update of application
3. Offset commit on source topics
위 3개를 하나의 트랜잭션으로 처리하지 못한다면 장애 상황에서 Exactly once를 만족하지 못하게 됩니다. 카프카 스트림즈는 위 3가지 과정을 트랜잭션으로 묶어서 원자성(atomic)을 달성하기 위해 2가지 기능을 사용합니다.
기능1) 카프카는 소스 토픽에 대한 응답(commit)을 인터널 카프카 토픽(offsets topic)에 등록합니다.
기능2) 스트림즈 라이브러리는 상태(state)를 저장하기 위해 changelog 토픽을 사용합니다. 프로세싱 중에 발생하는 각각의 상태를 토픽에 저장함으로서 고가용성을 달성합니다. 그리고 상태 저장에 대한 업데이트 히스토리를 토픽에 저장함으로써 source-of-truth(진실의 샘)역할을 합니다.
위와 같은 2가지를 활용하여 아래와 같은 3가지 과정에 대한 트랜잭션을 만족시킬 수 있습니다.
1. A batch of records sent to sink topics
2. A batch of records sent to changelog topics
3. A batch of records sent to the offset topic
추가적으로 트랜잭션API를 사용하여 스트림즈가 처리한 레코드들에 대한 sink 토픽, changelog 토픽, offset 토픽의 전송을 원자성(atomic)있게 처리할 수 있습니다. 추가적으로 처리한 레코드에 대한 전송은 멱등성 프로듀서로 전송되기 때문에 ack가 실패하더라도 딱 1번만 적재되게 됩니다.
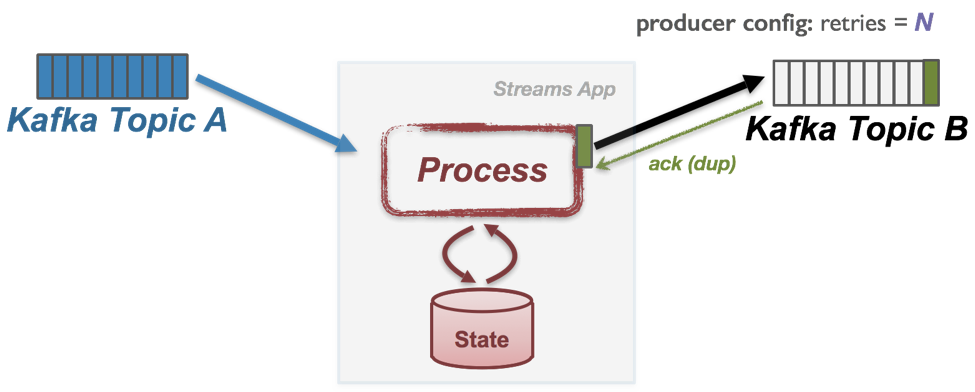
만약, 프로세싱 도중에 프로세서가 종료되더라도 해당 레코드 처리에 대한 상태는 트랜잭션처리되고 있기 때문에 무조건 성공적으로 저장됩니다.
여기서 성공적이라는 것은 무조건 처리(commit)되거나 롤백(abort)되는것을 뜻합니다.

카프카 스트림즈의 Exactly once처리와 퍼포먼스
이러한 처리과정은 at least once처리에 비해 transaction처리 비용이 발생합니다. Transaction 처리 비용을 낮추기 위한 방법은 1개의 트랜잭션에 레코드의 개수를 늘리는 방법입니다. 카프카 스트림즈에서 트랜잭션의 레코드 사이즈는 commit interval 옵션 사이에 들어오는 레코드의 수에 따라 다릅니다. 그렇기 때문에 commit.interval.ms를 늘리면 1번의 트랜잭션 처리에 포함되는 레코드 개수가 늘어나고 처리량이 늘어납니다. 그러나 그만큼 장애가 발생했을 경우에 원복하는데 시간이 오래 걸리죠. 반면에 commit.interval.ms를 줄이면 단위시간당 처리량은 줄어들고 장애발생시 원복시간은 줄어들게 됩니다.
정답은 없습니다. 처리량과 점대점 프로세싱 지연 둘 중 하나를 골라야합니다.
원본 문서
- https://www.confluent.io/blog/enabling-exactly-once-kafka-streams/
'빅데이터 > Kafka' 카테고리의 다른 글
| Cannot get state store TOPIC because the stream thread is STARTING, not RUNNING 에러 해결 (0) | 2021.06.16 |
|---|---|
| 카프카 스트림즈 KTable로 선언한 토픽을 key-value 테이블로 사용하기 (0) | 2021.06.16 |
| kafka spark structured stream 예제코드 및 실행 (0) | 2021.06.04 |
| 카프카 스트림즈 All stream threads have died. 오류 해결 방안 (0) | 2021.05.27 |
| ProducerRecord에 파티션 번호를 지정하면 어떻게 동작할까? (0) | 2021.05.05 |
| 카프카를 이벤트 소싱, CQRS로 사용할 수 있을까? (2) | 2021.05.03 |