
데이터 레이크란?
데이터 레이크의 기본 개념은 기업단위의 서비스 데이터들을 한곳의 저장공간에 모아 두는 것입니다. 이렇게 저장된 데이터로부터 BI(Business Intelligence) App으로 조회하거나 시각화, 머신러닝을 수행하였습니다. 데이터 웨어하우스와 다르게 '일단 저장'하고 나서 이후에 스키마를 적용하는 'Schema-on-Read'에 초점을 잡고 있습니다.
데이터 레이크라는 단어가 나온 이래로 지속 발전을 거듭했고 데이터 레이크 기술은 다음과 같이 발전 하였습니다.
- 1세대 데이터 레이크 : HDFS, 맵리듀스, 피그, 하이브, 임팔라, 플룸, 스쿱
- 2세대 데이터 레이크 : 클라우드 네이티브로 성장하였고 오브젝트 스토리지(S3), 스파크, 플링크, 프레스토, 스트림셋

스트리밍 데이터 레이크(aka. Kappa 아키텍처)
기존의 데이터 레이크는 배치성 데이터를 처리하는데 중점이 되었고 스트리밍 데이터를 처리해야 함에 따라 배치 데이터와 스트림 데이터를 융합하여 아키텍처를 만들어야 했습니다. 그렇게 나온 데이터 레이크 아키텍처가 바로 람다 아키텍처입니다. 람다 아키텍처는 배치 레이어와 스트림 레이어(또는 스피드 레이어)를 따로 두고 서빙 레이어를 통해 정합(merge)하고 쿼리(query)함으로서 전송 지연을 최소화하였습니다.
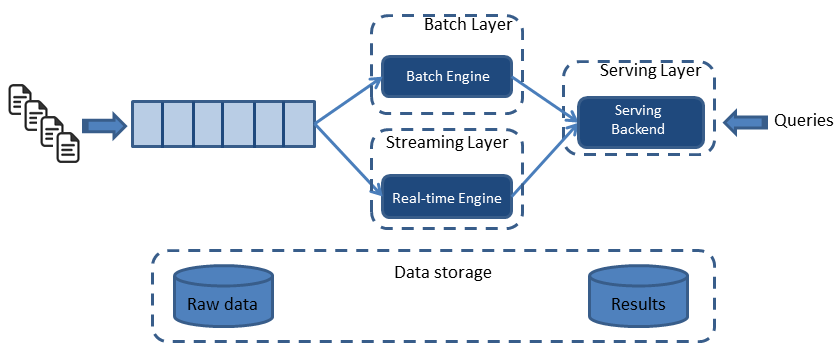
람다 아키텍처의 단점은 복잡함이였습니다. 두개의 다른 경로를 통하 아키텍처를 관리해야했고 파이프라인을 이중 관리해야한다는 복잡성이 있었습니다. 이로 인해 중복된 로직도 발생하였습니다. 이를 해소하기 위해 링크드인의 제이 크랩스(Jay Kreps)는 카파 아키텍처를 제안했습니다. 아파치 카프카의 창시자로도 널리 알려진 제이 크랩스는 과감히 배치 레이어를 제거하는 방식을 제안했습니다. 스피드 레이어에서 모든 데이터를 스트림 처리하여 스피드 레이어와 서빙 레이어로 이루어진 방식이였고 이것이 카파 아키텍처(Kappa) 아키텍처입니다.

카파 아키텍처 특성상 모든 데이터를 스트림 데이터로 분류하므로 이중으로 파이프라인들을 유지보수하지 않아도 되기 때문에 운영상 장점이 있습니다. 단순화된 레이어로 인해 운영시 디버깅과 테스트를 람다 아키텍처보다 수월하게 할 수 있다는 점도 있습니다. 하지만 스피드 레이어로 단일화된 만큼 레이어에서 장애가 발생하면 SPOF(Single Point Of Failure) 지점이 될 수 있기 때문에 카파 아키텍처 데이터 플랫폼 내부에서는 장애에서 자유로울 수 있도록 장애 허용 시스템(Fault tolerance System)으로 동작이 필요한 것이 특징입니다.

카파 아키텍처에서 이벤트 허브는 모든 이벤트(CDC, 이벤트 스트림)을 담는 그릇입니다. 이벤트 허브는 마치 버퍼처럼 동작하는데 카프카 클러스터를 이벤트 허브로 사용할 수 있습니다. 모든 데이터를 이벤트 허브에 넣은 다음 빅데이터 플랫폼에 저장되어야 하는 데이터는 벌크로 저장하고 스트리밍 프로세싱이 필요한 데이터는 스트림 프로세싱 플랫폼을 통해 데이터를 가공하여 다시 이벤트 허브(여기서는 카프카)에 저장합니다. 마치 이벤트 허브가 데이터 분기를 제공하는 것과 같은데, 이것을 '스트리밍 데이터 레이크'라고도 불립니다.
스트리밍 데이터 레이크는 카파 아키텍처와 일맥상통하다고 볼 수 있습니다. 이 아키텍처를 살펴보면 소스 오브 트루스(Source of Truth: 인사이트를 가지고 있는 파생 데이터)가 데이터 플랫폼에 위치하고 있음을 확인할 수 있습니다. 소스 오브 트루스가 데이터 플랫폼에 위치하고 있는 이유는 보통 버퍼로 사용하는 이벤트 허브의 저장 기간이 많아봐야 몇일밖에 되지 않기 때문입니다.

이벤트 허브에서 생성된 raw 데이터들은 데이터 플랫폼에서 Refine, Optimized 과정을 거치고 난 뒤 정재된 데이터를 통해 consumer(데이터를 사용하는 고객)이 데이터를 사용하게 됩니다.
그런데 꼭 데이터 플랫폼안에서 이런 스트리밍 처리를 해야할까요? 이벤트 허브를 소스 오브 트루스로 사용하는 것이 가능할까요?

이벤트 허브를 소스 오브 트루스로 사용한다는 뜻은 이벤트 허브의 데이터가 삭제되지 않는 다는 뜻과 동일합니다. 만약 이벤트 허브를 카프카로 사용하고 있다면 리텐션 기간을 무제한으로 두는 것이죠. 그렇게 변경한다면 이벤트 허브를 소스 오브 트루스로 사용할 수 있습니다.

이렇게 이벤트 허브를 소스 오브 트루스로 사용한다면 더이상 데이터 플랫폼에서 raw 데이터를 저장할 필요가 없어집니다. 즉, 데이터 플랫폼에서 사용하던 HDFS, 오브젝트 스토리지와 같은 데이터 저장소의 역할이 사라지는 것이죠. 왜냐면 모든 데이터가 이벤트 허브(카프카)에 존재하니까 필요한 데이터를 토픽단위로 찾아서 특정 토픽, 오프셋을 찾아서 리플레이하면 되기 때문입니다.
이벤트 허브를 소스 오브 트루스로 사용하는게 가능할까요?
제이 크랩스에 따르면 이벤트 허브를 카프카로 사용한다면 가능한 일이라고 말합니다.

위 그림과 같이 컨플루언트에서는 카프카를 마치 데이터베이스처럼 사용 가능하게 하며 로컬 스토리지를 사용하지 않고 카프카를 데이터 베이스처럼 사용 가능하게 합니다. 특히 컨플루언트 엔터프라이즈 카프카를 사용하면 카프카 브로커의 데이터 중 자주 접근하는(hot) 데이터는 브로커에 두고 자주 접근하지 않는(cold) 데이터는 오브젝트 스토리지에 둘 수 있게 만들 것입니다. 이러한 방식을 통해 카프카 클러스터의 스케일 조절을 더욱 효과적으로 할 수 있으며 안전하게 데이터를 저장할 수 있습니다.
카프카를 데이터 레이크로 사용하기 위한 방법
카프카를 데이터 레이커로서 그리고 소스 오브 트루스로 사용하기 위해서는 기존의 저장소(S3, HDFS)의 접근 방법과는 다르게 생각해야 합니다. 카프카의 토픽에 저장된 레코드는 스트리밍 데이터로 끝없이 이어져 있기 때문에 스트리밍 쿼리인지 배치 쿼리인지에 따라 토픽의 데이터 접근방법이 달라집니다. 기존에 데이터를 접근하던 SQL방식 접근법는 다르 다는 것을 인지해야합니다.
스트리밍 쿼리의 경우
- Latest : 가장 최신의 데이터부터 읽기
- Earliest : 가장 오래된 데이터부터 읽기
- Seek to offset : 특정 오프셋을 기준의 데이터부터 읽기
- Seek to timestamp : 특정 타임스탬프를 기준의 데이터부터 읽기
배치 쿼리의 경우
- From start offset to end offset : 시작 오프셋의 데이터와 끝 오프셋의 데이터 사이에 있는 데이터를 읽기
- From start timestamp to end timestamp : 시작 타임스탬프의 데이터와 끝 타임스탬프의 데이터 사이에 있는 데이터를 읽기
- Full scan : 토픽의 모든 데이터를 읽기
카프카를 데이터 레이크로 사용하는 4가지 아키텍처 방안
1안) 스트리밍 데이터 레이크(ksqlDB와 카프카 스트림즈 기반)


2안) 이벤트 허브 기반 배치 프로세싱(아파치 스파크 기반)
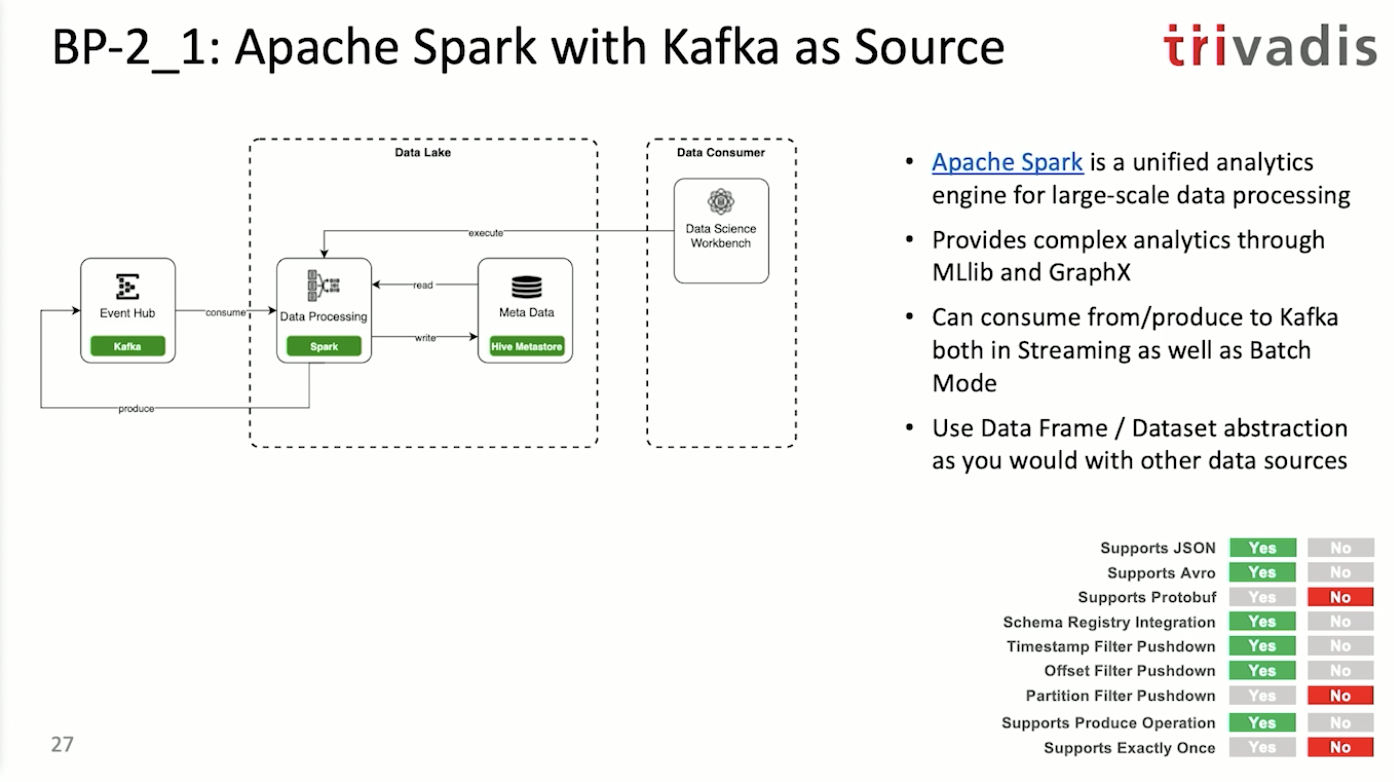
Data Science Workbench는 Jeppelin, Jupyter lab과 같은 툴을 뜻합니다.
Structured Streaming + Kafka Integration Guide
→ spark.apache.org/docs/latest/structured-streaming-kafka-integration.html
# topic1 컨슘(스트리밍 쿼리 by python)
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("subscribe", "topic1") \
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
3안) 이벤트 허브 기반 배치 쿼리(Presto 기반 또는 아파치 drill 기반 또는 Hive/Spark SQL 기반)

Presto → prestodb.io/
Presto kafka connector → prestodb.io/docs/current/connector/kafka.html

Apache drill - Kafka Storage Plugin → drill.apache.org/docs/kafka-storage-plugin/

Apache Hive-Kafka integration → docs.cloudera.com/HDPDocuments/HDF3/HDF-3.5.1/kafka-hive-integration/content/hive-kafka-integration.html

Oracle SQL Access to Kafka → docs.oracle.com/en/bigdata/big-data-sql/4.1/bdsug/oracle-sql-access-kafka1.html
4안) 스토리지 기반

만약 이벤트 허브에 데이터들이 모아진다면 이벤트 허브를 싱글 소스 오브 트루스로 볼 수 있습니다. 이벤트 허브로 부터 오브젝트 스토리지나 RDBM에 데이터를 옮겨 넣을 수 있죠. 왜냐면 데이터를 사용하시는 분들(Data scientist, Engineer 등)은 이런 스토리지 기반 접근에 친숙하기 때문입니다. 위와 같은 구조를 가져가기 위해서는 데이터 레이크를 샌드박스(Sand box)처럼 운영해야합니다. 데이터는 모두 이벤트 허브에 있되, 원천 데이터로 부터 파생 데이터를 만들고 인사이트를 찾는 것은 데이터 레이크의 저장소에서 활용하는 것이죠.
1~4안 종합)

결론
- 프로세싱, 분석은 배치에서 스트리밍 프로세싱 파이프라인으로 변화하는 중
- 카프카를 이벤트 허브로로 사용하여 싱글 소스 오브 트루스로 사용할 수 있음!
- 여타 저장소들(NoSQL, 인메모리 DB 등)는 이벤트 허브의 데이터를 확인하는 용도로 사용됨.
- 컨플루언트 플랫폼(엔터프라이즈)는 카프카를 데이터 레이크로서 더 긴 기간 데이터를 저장하는데 사용할 수 있도록 개선 중임.
- 이러한 데이터 레이크는 큰 용량의 이미지, 비디오 등의 데이터는 지원하지 않음. => 메타데이터를 저장하는데는 사용 가능.
제이 크랩스가 발표한 이 내용은 사실 2020년 기준으로는 청사진에 가깝고 PoC(Proof of Concept) 수준에 있습니다. 하지만 컨플루언트에서는 카프카를 데이터 레이크로 그리고 소스오브 트루스로 사용할 수 있도록 점차 변화를 꽤하고 있습니다. 빠른 시일 내에 카프카 기반 데이터 레이크가 만들어질 것으로 보입니다.
레퍼런스
영상 출처 : www.confluent.io/resources/kafka-summit-2020/kafka-as-your-data-lake-is-it-feasible/
오랠리(Applying the Kappa architecture in the telco industry) : www.oreilly.com/content/applying-the-kappa-architecture-in-the-telco-industry/
'빅데이터 > Kafka' 카테고리의 다른 글
| 카프카 스트림즈 애플리케이션 초기화 명령 (0) | 2021.03.31 |
|---|---|
| local kafka single broker 띄우기 with 도커 (0) | 2021.03.05 |
| 특정 시점(날짜+시간)의 레코드부터 가져오도록 설정하기. (2) | 2021.03.03 |
| macOS에서 카프카 버로우 빌드 및 실행하기. (0) | 2020.11.29 |
| 카프카 토픽의 오프셋 최대 크기는 얼마일까? (0) | 2020.11.17 |
| 카프카 커넥터 빌드시 JDK11이 아닌 JDK8로 그래들 빌드해야합니다. (2) | 2020.11.02 |