
오늘 카프카 컨슈머를 입수하던 도중 매우 신기한 현상을 발견해서 기록하게 되었습니다. 컨슈머스레드를 여러개로 HDFS에 적재하고 있었는데, 일부 파티션의 데이터가 0이 되어 일부 컨슈머 스레드가 쉬는동안 총 처리량이 늘어난 것입니다. 그래프를 보면서 왜 그렇게 되었는지 확인해보겠습니다.
입수 상태
- 24 core, 48G memory 물리장비
- 1 JVM application
- 20 consumer thread
- sync offset commit
- save at Hadoop hdfs(append)
입수 관련 그래프

컨슈머 랙은 카프카 버로우를 사용하여 수집중에 있습니다. 랙 추이를 보면 알겠지만 파티션당 데이터 양의 차이가 일부 발생하였습니다. 10개 파티션은 18:20 부근에 끝났고 나머지 10개 파티션은 18:45 부근에 랙이 0으로 수렴하였습니다. 위 그래프에서 재밌는 사실은 18:20 부근에 파티션 10개의 랙이 0으로 될 때 입니다. 18:20 부근에 파티션 랙이 줄어드는 기울기가 급격하게 바뀌는 것을 볼 수 있습니다.
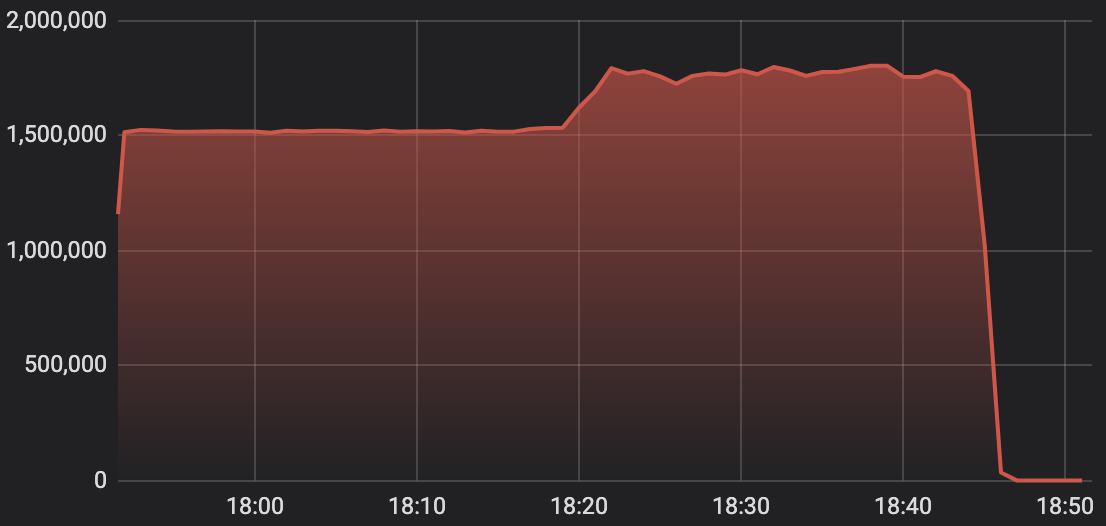
위 그래프는 애플리케이션에 입수하는 총 입수량 그래프입니다. 컨슈머 랙이 줄어드는 기울기가 급격하게 변하는 순간(18:20) 애플리케이션에서 입수하는 총 입수량이 113% 늘어난 것을 볼 수 있습니다.
컨슈머 스레드가 처리하는 시간당 처리량은 제한되어 있으니 당연히 애플리케이션의 총 입수량은 그대로일거라 생각했지만 실상은 달랐습니다. 일부 스레드가 컨슈머 랙이 0으로 되는 순간 다른 스레드의 처리량이 기존보다 늘어나면서 오히려 처리량은 늘었습니다. 위와 같은 그래프가 발생하게된 원인은 스레드 컨텍스트 스위칭으로 인해 발생하는 것으로 추정됩니다.
스레드 컨텍스트 스위칭이란 프로세스가 실행되는 동안 여러 스레드가 돌아가게 되는데, 스레드처리를 하면서 다른 스레드로 작업을 넘기는 과정인데 주로 Context정보를 넘깁니다. 10개 스레드가 파티션의 데이터가 없어 더이상 처리를 안하게 되니까 나머지 스레드간의 컨텍스트 스위칭 빈도수가 현저히 줄어들어 시간당 처리량이 늘어난 것으로 보입니다.
그런데 문제는 카프카 컨슈머를 개발하다보면 보통 토픽의 처리량을 늘리기 위해서는 보통 파티션 개수와 스레드 개수를 늘린다는 점입니다. 파티션 개수를 늘리면 1:1 매칭할 수 있는 컨슈머 스레드 개수를 늘리는데, 위 그래프에 따르면 무조건 스레드 개수를 늘린다고 처리량이 많아진다고 볼 수 없습니다. 오히려 스레드 개수가 줄어들면서 처리량이 늘었거든요.
위와 같은 상황에서 처리량 증대를 위해 선택할 수 있는 선택지는 크게 2가지가 있을것 같습니다.
1안) 컨슈머 스레드의 개수를 줄이기
2안) 스케일 아웃하기(스레드 분산)
1안의 경우 컨텍스트 스위칭 빈도를 줄이는데 효과적일 수 있습니다. 파티션 개수에 비해 컨슈머 스레드 개수를 줄이게 되면 2개 이상의 파티션이 컨슈머 스레드에 할당되기 때문에 컨슈머 버퍼에 데이터가 이전보다 더 많아질 수 있습니다. 하지만 컨텍스트 스위칭 빈도는 줄어들기 때문에 더욱 나은 성능을 기대할 수 있습니다.
2안의 경우 가장 전통적이고 확실한 방법입니다. 스케일 아웃을 통해 서버2대에 프로세스를 분산하고 스레드도 분산하는 전략입니다. 이렇게 수행할 경우 컨텍스트 스위칭 빈도도 줄어들고 총 처리량도 늘어나기 때문에 매우 높은 성능을 기대할 수 있습니다. 다만, 여러대의 서버를 관리하는 방안을 고민해야합니다.(로그수집, 방화벽 등)
위 2개의 안은 직접 테스트를 통해 유추한 결과가 아니며 실제 동작에서 정 반대의 성능을 발생시킬 수 있습니다.
그런데 카프카 컨슈머를 통한 빅데이터 입수에서 무엇보다 중요한건 위와 같이 관련 데이터를 남기는 것입니다. 컨슈머 랙과 총 입수량 데이터를 남기지 않았다면 이러한 분석도 못햇을 것입니다. 그리고 추후 1안 또는 2안 으로 처리한다고 하더라도 실제로 처리량이 늘었는지 확인하려면 관련 데이터를 남기고 또 수집해야만합니다.
꼭 기록을 남기세요.
'빅데이터 > Kafka' 카테고리의 다른 글
| 스프링 카프카 메시지 리스너 2가지 구현 방법 (0) | 2020.07.23 |
|---|---|
| 카프카 컨슈머 파티셔너 종류 및 정리(2.5.0 기준) (1) | 2020.07.23 |
| 카프카 프로듀서 파티셔너 종류 및 정리(2.5.0 기준) (1) | 2020.07.23 |
| kafka connector distributed 모드로 fileSourceConnector 실행 (2) | 2020.07.21 |
| Kafka file source connector standalone 모드 실행 (2) | 2020.07.21 |
| Kafka-client 사용시 Failed to load class "org.slf4j.impl.StaticLoggerBinder" 에러 해결 방법 (2) | 2020.07.13 |