
실시간으로 비디오 및 데이터 스트림을 손쉽게 수집, 처리 및 분석 솔루션
Amazon Kinesis를 사용하면 실시간 스트리밍 데이터를 손쉽게 수집, 처리 및 분석할 수 있으므로 적시에 통찰력을 확보하고 새로운 정보에 신속하게 대응할 수 있습니다.
Amazon Kinesis 기능
- Kinesis Video streams : 비디오 스트림을 캡처 처리 및 저장
- Kinesis Data streams : 데이터 스트림을 캡쳐, 처리 및 저장
- Kinesis Data firehose : 데이터스트림을 AWS데이터 스토어로 로드
- Kinesis Data analytics : SQL 또는 Java를 통해 스트림 데이터를 분석
이번 포스팅에서 주요하게 볼 서비스는 Data firehose 입니다.
Data firehose 아키텍처
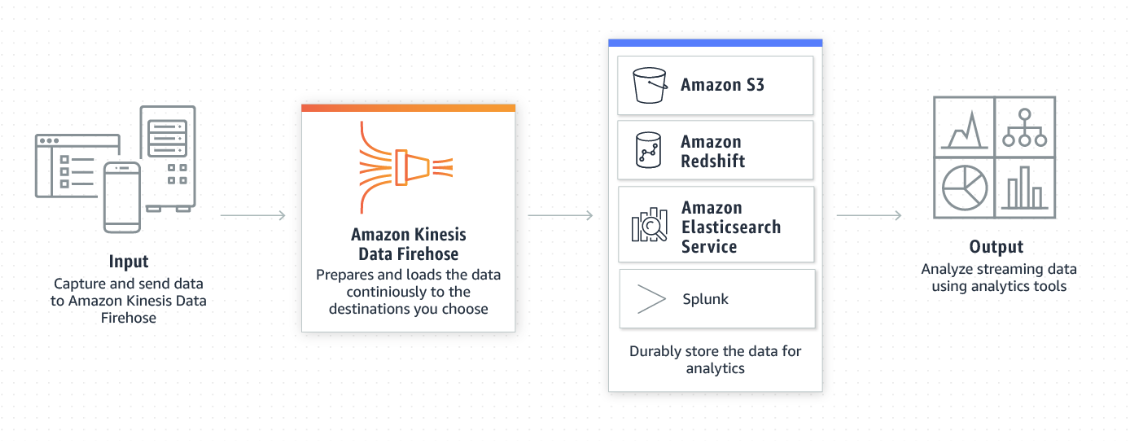
Amazon Kinesis Firehose 시작
1. Kinesis리소스 선택하기
Kinesis를 사용하기 위해 리소스를 선택할 수 있습니다. 먼저 Data streaming 저장용도로 사용할 Firehose를 선택하여 스트림을 생성하고 적재해보겠습니다. Firehose는 스트리밍 데이터를 데이터 레이크 혹은 스토어/분석도구에 쉽고 안정적으로 로드할 수 있습니다.
AWS의 설명에 따르면 Firehose로 전송된 뒤 60초 이내에 S3/Redshift/Elasticsearch/splunk로 로드가 가능하다고 합니다. 또한 스트리밍 데이터의 용량에 따른 관리를 AWS에서 자체적으로 수행하기 때문에 추가적인 관리가 필요없다고 합니다.

2. 5가지 step 수행
Kinesis firehose를 생성하기 위해서는 5가지 step을 수행해야합니다.
1) Name and source
Delivery stream 이름을 정하고, source를 정합니다. Delivery stream 이름은 영어 소문자,대문자, 숫자, underscore, hypen을 지원합니다.

데이터 source는 직접(Direct) PUT하는 방식과 또다른 Kinesis Datastream으로 부터 받는 방식 2가지 방식을 지원합니다.

추가적으로 delivery stream에 대한 권한을 관리하고 싶다면 AWS KMS(Key management service)를 통해 접근권한을 줄 수 있습니다.
2) Process records
record에 대한 transform 을 수행할 것인지에 대해 설정합니다. 두가지 단계를 거칠 수 있게 제공하는데, 해당 프로세스 아키텍쳐는 아래와 같습니다.

AWS Lambda를 통해 source record에 대해 암/복호화, 기타 비즈니스 처리를 수행할 수 있습니다. 만약 필요하지 않다면 disable(사용하지 않음)도 가능합니다.
Convert record format기능으로 record에 대해 output format을 Apache parquet 혹은 ORC로 정의할 수 있습니다. 다만, Parquet, ORC 모두 schema가 포함된 record이기 때문에 기 선언된 Glue와의 연동이 필요합니다. 아래는 output format을 선언하고 Glue를 설정하는 창 입니다.
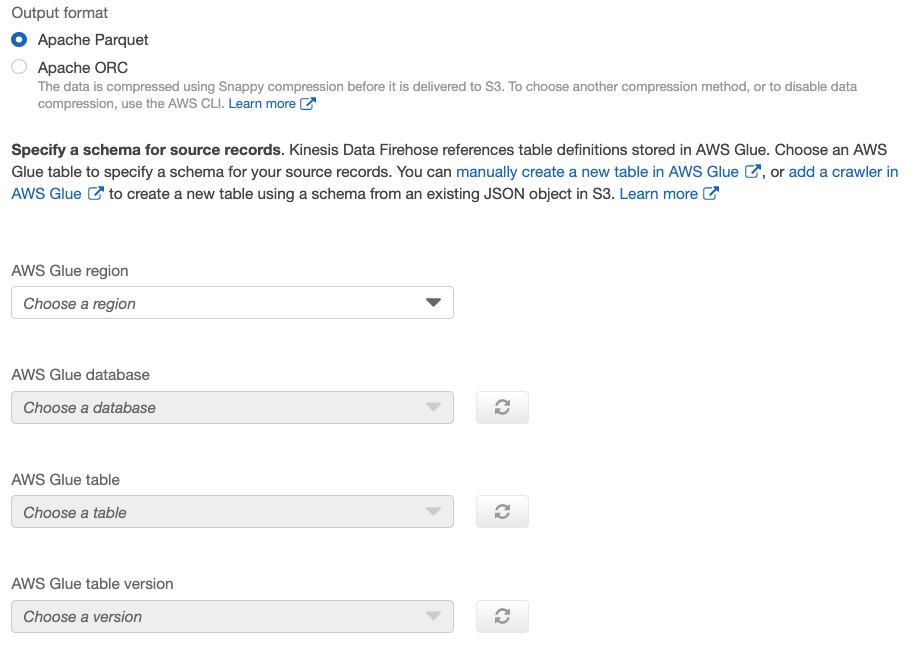
3) Choose a destination
2단계까지 변환된 record에 대해 어디에 저장할 것인지에 대한 destination을 정할 수 있습니다. 서울 region 19년 12월 기준 S3, Redshift, Elasticsearch, Splunk를 지원합니다.
이 때 주의할 점은 2개 이상의 destination을 정할 수 없다는 점입니다. 1개 firehose에 대해서 1개의 destination만 선언할 수 있습니다. 이는 Kafka가 서로다른 group Id로 다양한 destination에 적재할 수 있다는 점과는 사뭇 다른 점입니다.
그리고 각 저장소마다 각기 다른 data flow로 장애에 대응하기 때문에 이점을 잘 파악하여 운영하는것이 중요해 보입니다.

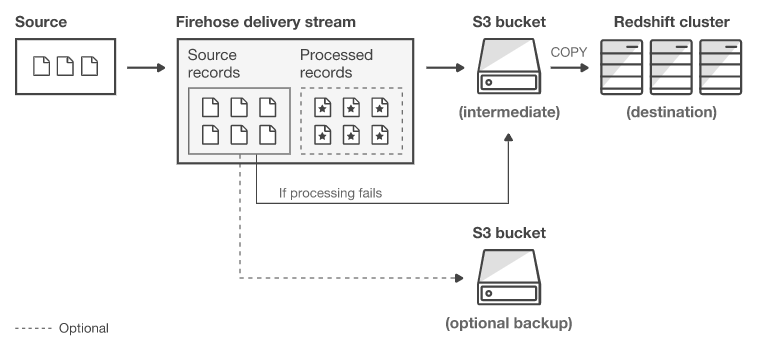
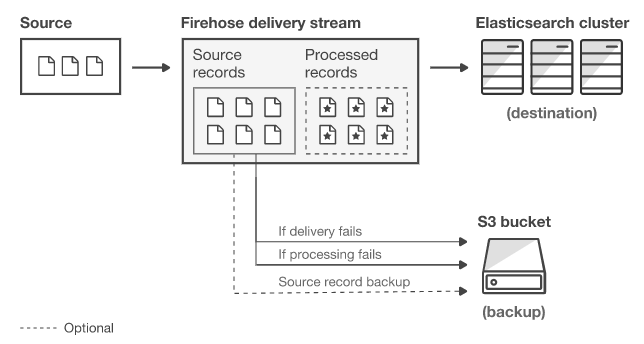

Destination선택이 끝나면 Destination에 대한 추가적인 옵션을 정의해야합니다. 이번에는 S3를 destination으로 정했기 때문에 아래와 같은 정보를 작성해야합니다.
- S3 bucket name : 이미 존재하는 S3에 넣을 수도 있고 혹은 신규로 생성도 가능합니다.
- S3 prefix, error prefix : UTC기준 YYYY/MM/DD/HH 로 기본적으로 적재하지만 추가적으로 상황에 따라 directory name에 prefix를 넣을 수 있습니다. 이 directory naming을 위한 변수는 aws에서 지정한 변수를 넣으면 됩니다.

4) Configure settings
추가적인 configure을 선언할 수 있습니다. S3 destination으로 지정하였으므로 S3관련 옵션을 선택할 수 있습니다.
- S3 buffer conditions : Buffer size/interval을 통해 flush timing을 지정할 수 있습니다. 최소 buffer size는 1MB, 최소 interval은 1분입니다.
- S3 compression and encryption : GZIP, Snappy, Zip으로 압축할 것인지 지정가능합니다. KMS로 열수 있는 파일로 encryption할 것인지 지정할 수 있습니다.
- Error logging : 에러가 발생했을 경우 Cloudwatch log로 남길지 지정할 수 있습니다.
- Tag
- IAM permission : IAM permission을 지정합니다.
5) Review
앞서 1)~4) 까지 선언한 설정들에 대해 재확인할 수 있습니다.
3. 생성완료
생성이 완료되고 나면 아래와 같이 delivery stream이 생성된 것을 확인할 수 있습니다.

4. Data를 Firehose에 넣기
Data를 Firehose에 넣기 위해서는 아래와 같은 방식을 사용할 수 있습니다.
- Amazon Kinesis Agent : Kinesis agent는 Java application입니다. 이 agent를 통해 file 단위 data를 \n 단위의 record로 나누어서 데이터를 전송할 수 있습니다.
- Firehose API using the AWS SDK : AWS SDK(Java, .NET, Node.js, Python, Ruby)를 통해 Kinesis로 데이터를 전송할 수 있습니다. 혹은 Kinesis전용 client library를 사용할 수도 있습니다. PutRecord, PutRecordBatch와 같은 method를 통해 데이터를 batch단위로 혹은 record단위로 전송할 수 있습니다.
- ETC : AWS Iot, Cloudwatch logs, events.의 데이터를 직접 연결할 수 있습니다.
이번 시간에는 AWS SDK Java을 통해 json데이터를 전송해보겠습니다.
Sample code는 Gradle을 사용하여 build하였고 Java 8을 기반을 하였습니다. Firehose를 사용하기 위한 디펜던시와 code는 아래와 같습니다.
build.gradle
plugins {
id 'java'
}
group 'kinesis'
version '1.0-SNAPSHOT'
sourceCompatibility = 1.8
repositories {
mavenCentral()
}
dependencies {
testCompile group: 'junit', name: 'junit', version: '4.12'
compile group: 'com.amazonaws', name: 'aws-java-sdk', version: '1.11.695'
compile group: 'com.amazonaws', name: 'amazon-kinesis-client', version: '1.13.0'
}Main.java
import com.amazonaws.auth.AWSStaticCredentialsProvider;
import com.amazonaws.auth.BasicAWSCredentials;
import com.amazonaws.services.kinesisfirehose.AmazonKinesisFirehose;
import com.amazonaws.services.kinesisfirehose.AmazonKinesisFirehoseClientBuilder;
import com.amazonaws.services.kinesisfirehose.model.PutRecordRequest;
import com.amazonaws.services.kinesisfirehose.model.PutRecordResult;
import com.amazonaws.services.kinesisfirehose.model.Record;
import java.nio.ByteBuffer;
public class Main {
public static void main(String args[]) {
BasicAWSCredentials awsCreds = new BasicAWSCredentials("accessKey",
"secretKey");
AmazonKinesisFirehoseClientBuilder clientBuilder = AmazonKinesisFirehoseClientBuilder.standard();
clientBuilder.setRegion("ap-northeast-2"); // 서울 region
clientBuilder.setCredentials(new AWSStaticCredentialsProvider(awsCreds));
AmazonKinesisFirehose kinesisClient = clientBuilder.build();
// 100번 반복해서 전송
for (int i = 0; i < 100; i++) {
sendData(kinesisClient, i);
}
}
static void sendData(AmazonKinesisFirehose kinesisClient, int count) {
String myData = "{\"no\":" + count + "}\n"; // 보내려는 데이터
PutRecordRequest putRecordsRequest = new PutRecordRequest();
putRecordsRequest.setDeliveryStreamName("rake_to_s3");
Record rc = new Record();
rc.setData(ByteBuffer.wrap(myData.getBytes()));
putRecordsRequest.setRecord(rc);
PutRecordResult putRecordsResult = kinesisClient.putRecord(putRecordsRequest);
System.out.println("Put Result" + putRecordsResult);
}
}위 코드에서 주의하실점은 AmazonKinesisFirehose class를 사용한다는 점입니다. AmazonKinesis class를 사용하게 되면 ResourceNotFound Exception: Stream Not found 400 에러가 발생하니 주의하시기 바랍니다.
5. 실행결과
위 Java application을 실행하고 정상적으로 진행되었을 경우 destination으로 설정한 S3에 평문으로 저장하게 됩니다. flush되는 타이밍은 4) configure에서 설정한 값을 따라갑니다.


Amazon Kinesis Firehose 소감 및 의견
오늘 포스팅에서는 Kinesis Firehose를 구현하여 실시간 S3적재 파이프라인을 만들어 보았습니다. 모든 과정이 순조로웠고 결과까지 확인하는데 몇시간 걸리지 않았습니다. 이렇게 구축한 파이프라인은 AWS에서 Full management하기 때문에 현업에서 운영으로 사용해도 무방할 정도라고 보셔도 좋습니다.
On-promise에서 이와 같은 데이터 파이프라인과 적재시스템을 만드려면 엄청난 개발, 운영 resource가 들어갈 것임에 틀림없습니다. 당장 생각해보더라라도 Kafka broker(최소 3대 이상), Security 이슈, Producer, Consumer(with S3 SDK) 가 필요하고 당장 개발을 하여 구축 하더라도 추후 해당 서버들을 운영하고 OS/application upgrade를 하는데는 지속적인 비용이 투입되게 됩니다.
반면 Kinesis Firehose는 하루만에 데이터 입수 파이프라인을 생성할 수 있으므로 소규모 스타트업, 그리고 빠르게 데이터를 입수해야하는 needs가 있는 조직에게 큰 도움이 될 수 있습니다.
다만 몇가지 사용시 주의해야할 점이 있습니다.
Kinesis Firehose 사용시 주의점:
- Multiple destination 지정 불가능 ← 치명적
- Record format은 Raw, Parquet, ORC 만 지원
- Destination은 S3, Redshift, Elasticsearch, Splunk 만 지원
- Buffer size는 최대 128MB까지, Buffer interval은 최소 1분, 최대 15분
- UTC기준으로 directory partitioning(KST기준으로 변경 불가) ← 치명적
위와 같은 몇가지 이슈로 인해 Firehose는 당장 급한 불(데이터 입수)를 끄는데는 유용하지만, 추후 Multiple destination에 저장을 하거나 Hadoop 혹은 on-promise로 저장소를 옮기고자 할때는 매우 큰 장애물로 다가옵니다.
FireHose 서비스는 강력하고 빠르지만 Lock-in될 가능성이 높고 확장성이 매우 떨어집니다. 기업에서는 특정 제품에 락인(Lock-in)되는 것을 경계해야만 하므로 추후 확장가능성이 있는지를 살펴보고 Firehose를 사용하는 것을 추천합니다. 혹은 아래와 같은 방식으로 Firehose를 단계별로 나누어 사용한다면 추후 비즈니스 요구사항에 따라 Destination을 변경할 수 있도록 유연하게 설계하는 것도 좋은 방법으로 보입니다.
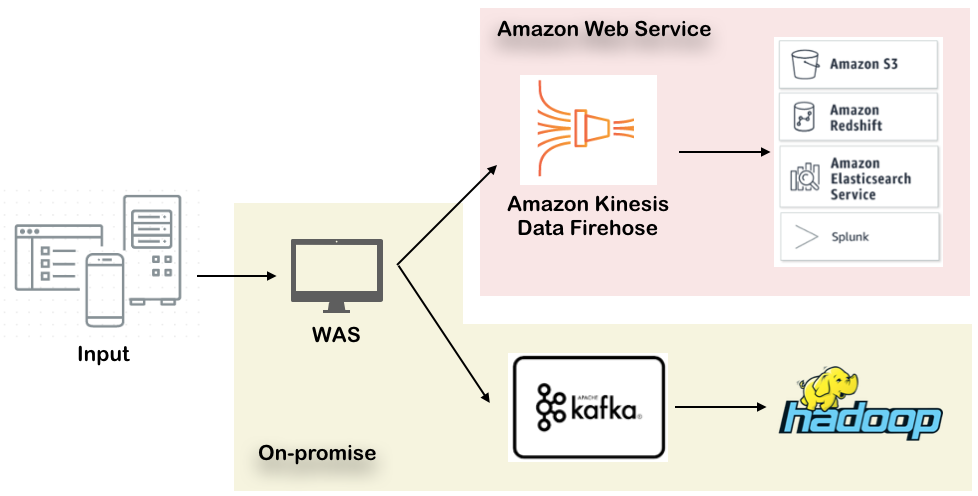
추가정보
가격
Kinesis Firehose는 수집되는 데이터 볼륨을 기준으로 비용이 청구됩니다.
만약 lambda나 format변환이 있다면 추가 비용이 발생합니다.
또한 저장소(s3, redshift등)의 비용은 따로 청구 됩니다.

사전 정보
- S3 적재
- format 변환 없음
- 한달 85TB 사용
계산
Kinesis Firehose 비용
- 85TB/month 사용 → 서울 region기준 GB당 0.036USD 적용
- 85,000GB * 0.036 USD/GB = 3,060USD(한화 약 356만원)
S3 storage(standard) 비용
- 85TB/month 사용 → 서울 region기준 GB당 0.024USD 적용
- 85,000GB * 0.024 USD/GB = 2,040USD(한화 약 237만원)
기타
Kinesis Data Firehose SLA : 99.9%
→ 1달에 0.7시간 서비스 down time 존재
→ 1년간 8시간 서비스 down time 존재
1 record 전송 최대 크기 : 1,000KB
'개발이야기 > AWS' 카테고리의 다른 글
| aws ec2에 openJDK 1.8 설치하기 실습 예제 (0) | 2020.06.01 |
|---|---|
| EC2 SLA(서비스 계약 수준) 에 따른 uptime, downtime 시간 계산 (0) | 2020.05.28 |
| elasticbeanstalk + route53 으로 SSL(443) 접속 flask application 생성하는 가장 간단한 방법 (0) | 2020.05.15 |
| AWS MSK(Kafka) 실습 및 예제 코드(Java), 장단점, 가격 (3) | 2019.12.26 |
| AWS kinesis Data stream 실습 및 예제 코드(Java), 장단점, 가격 (0) | 2019.12.23 |
| Spring boot에 AWS Elasticbeanstalk의 ebextensions 적용하기 (0) | 2018.11.19 |