
Telegraf는 influxdata(사)에서 opensource로 제공하는 plugin 기반의 metric수집 server agent이다.
github url : https://github.com/influxdata/telegraf
telegraf의 역할이 이해하기 어렵게 느껴질 수 있는데, 간단히 말하자면 아래와 같이 input, process, output이 가능하다.
Telegraf로 할 수 있는 일
- System의 ram, cpu수치를 elasticsearch에 적재
- Redis의 data를 elasticsearch에 적재
- File log를 influxdb에 적재
즉, input plugin으로 뽑아낸 데이터를 output plugin이 지원하는 곳으로 보낼 수 있다.
System metric을 elasticsearch로 보내기

System metric을 elasticsearch에 보내기 위해서는 아래와 같이 telegraf의 설정이 필요하다.
# telegraf agent 셋팅
# telegraf가 설치된 폴더의 etc/telegraf.conf 에 설정
[agent]
interval = "10s"
round_interval = true
metric_batch_size = 1000
metric_buffer_limit = 10000
collection_jitter = "0s"
flush_interval = "10s"
flush_jitter = "0s"
precision = ""
debug = false
quiet = false
hostname = ""
omit_hostname = false
### OUTPUT
[[outputs.elasticsearch]]
## 엘라스틱 서치의 full url을 적는다.(http/https 필수)
urls = [ "http://1.123.123.123:9200" ] # required.
## 엘라스틱 서치 타임아웃 시간
## 반드시 agent interval보다 긴 시간으로 설정한다.
## > 그렇지 않으면 context deadline exceeded 에러가 발생한다.
timeout = "60s"
enable_sniffer = false
health_check_interval = "10s"
## elasticsearch에 사용할 index name 설정
index_name = "my-computer-metric-%Y.%m.%d" # required.
## 만약 telegraf가 template를 자동으로 만들게 하고싶다면 true로 변경
manage_template = false
template_name = "telegraf"
overwrite_template = false
### INPUT
## 아래 값들은 system metric을 수집하기 위한 plugin이다.
# Read metrics about cpu usage
[[inputs.cpu]]
## Whether to report per-cpu stats or not
percpu = true
## Whether to report total system cpu stats or not
totalcpu = true
## Comment this line if you want the raw CPU time metrics
fielddrop = ["time_*"]
# Read metrics about disk usage by mount point
[[inputs.disk]]
## By default, telegraf gather stats for all mountpoints.
## Setting mountpoints will restrict the stats to the specified mountpoints.
# mount_points = ["/"]
## Ignore some mountpoints by filesystem type. For example (dev)tmpfs (usually
## present on /run, /var/run, /dev/shm or /dev).
ignore_fs = ["tmpfs", "devtmpfs"]
# Read metrics about disk IO by device
[[inputs.diskio]]
## By default, telegraf will gather stats for all devices including
## disk partitions.
## Setting devices will restrict the stats to the specified devices.
# devices = ["sda", "sdb"]
## Uncomment the following line if you need disk serial numbers.
# skip_serial_number = false
# Get kernel statistics from /proc/stat
[[inputs.kernel]]
# no configuration
# Read metrics about memory usage
[[inputs.mem]]
# no configuration
# Get the number of processes and group them by status
[[inputs.processes]]
# no configuration
# Read metrics about swap memory usage
[[inputs.swap]]
# no configuration
# Read metrics about system load & uptime
[[inputs.system]]
# no configuration
# Read metrics about network interface usage
[[inputs.net]]
# collect data only about specific interfaces
# interfaces = ["eth0"]
[[inputs.netstat]]
# no configuration
[[inputs.linux_sysctl_fs]]
# no configuration상기와 같이 설정하고, telegraf를 실행하면 elasticsearch에 data를 전송을 시작한다.
Elastic search의 data 확인
elasticsearch에 telegraf가 수집한 데이터가 잘 들어왔는지 확인하기 위해서 kibana를 사용했다.
kibana를 사용해서 index template를 'my-computer-metric-*'로 설정하고 나면 조회가 가능하다.

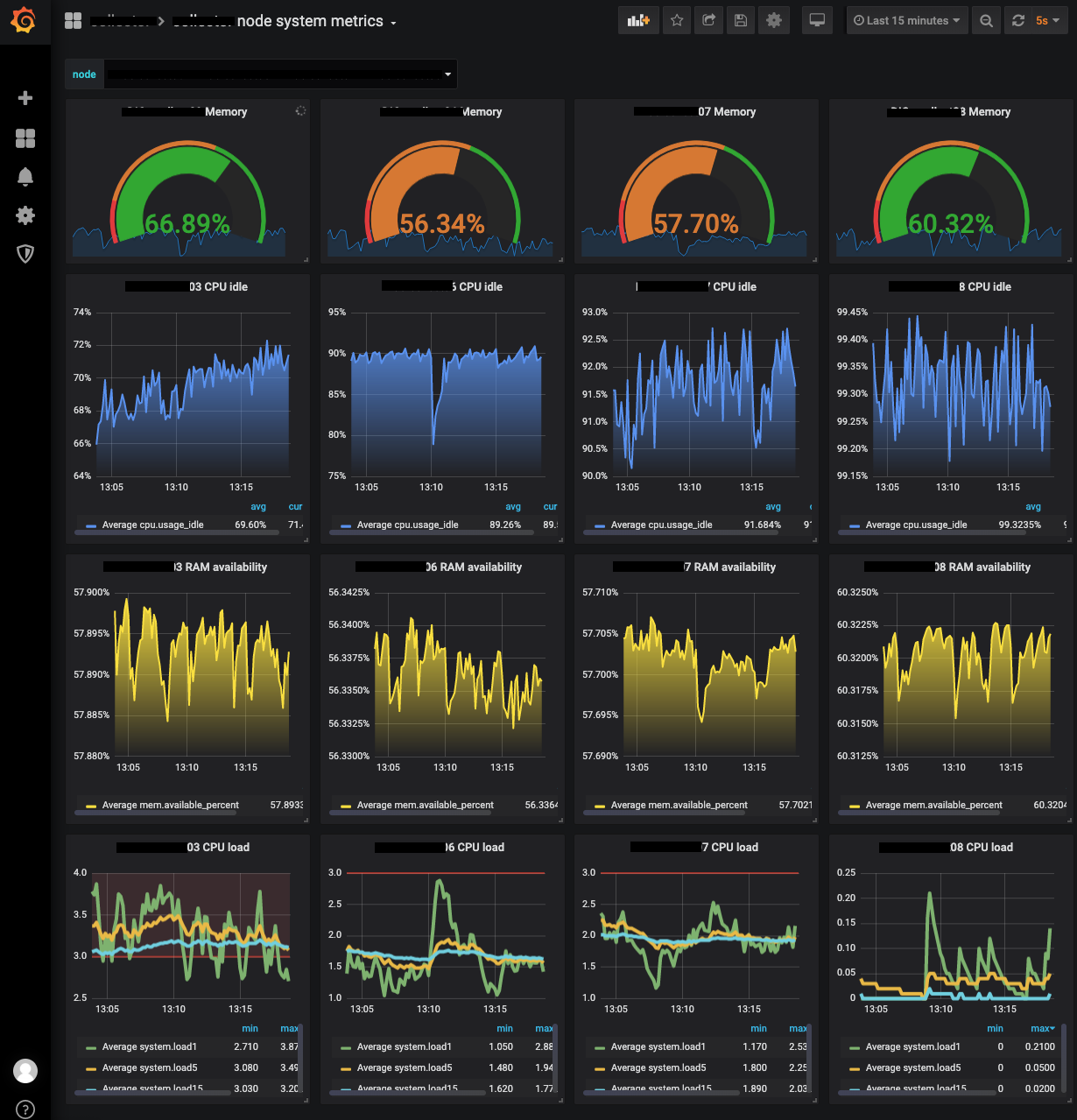
System metric data의 시각화
시각화 하는 방법은 여러가지가 있지만 개인적으로 grafana를 선호하기 때문에 grafana dashboard로 만들었다.
Grafana는 elasticsearch의 시각화도 강력한 기능과 함께 지원되는데, lucene query를 잘 활용하면 된다.
elasticsearch의 lucene query를 활용하여 grafana 대시보드를 그리는 포스팅은 조만간 자세히 포스팅 할 예정
'DevOps' 카테고리의 다른 글
| aws centos6에서 grafana 빌드하기 (0) | 2020.08.20 |
|---|---|
| Grafana 알람 사용시 Image Renderer 사용 이슈 정리 (0) | 2019.12.09 |
| Grafana와 엘라스틱서치 사용시 각종 query 조건 사용 방법(and, or, regex 등) (0) | 2019.10.11 |
| 넷플릭스에서 리눅스 퍼포먼스 체크하기(in 60초) (0) | 2019.08.27 |
| Slack으로 process가 정상적으로 시작되었는지 나타내는 이쁜 메시지 만들기(Incoming webhook과 Attachment message 활용) (0) | 2019.06.21 |