

5가지 NoSQL에 대해 알아보자
- MongoDB
- Redis
- hBase
- Cassandra
- DynamoDB
등장배경
1) 대량의 데이터를 Read/Write 할 필요성 증가
2) 지속적으로 증가하는 사용자에 대한 신속한 증가
3) 빠르게 변화하는 비즈니스에 대한 신속한 대응
4) 비정형 데이터의 폭발적 증가
관계형 데이터베이스의 한계가 커짐. 데이터는 커져만 가는데, 관계형 데이터베이스로는 저장/관리 힘듦. scale out하기에 기존 RDB(Relational Data Base)는 많은 비용을 지불해야 함.
NoSQL
Not Only SQL은 비관계형 데이터 스토리지 시스템, 비정형 데이터베이스들을 통칭한다. 고정된 테이블 스키마와 조인개념을 사용하지 않도록 모델링한다. ACID(원자성, 일관성, 고립성, 지속성) 속성은 유연하게 적용함. 대부분 open source로 공개되어 있다. scale out가능한 구조. RDB로는 해결이 되지 않는 부분 존재함. 자동화된 장애 극복, 복구 가능. 대규모 데이터 처리에 있어 RDB의 낮은 성능(비용대비 성능).
NoSQL에서도 RDB처럼 스키마는 존재한다. 다만 RDB는 스키마가 DB application을 가지고 있으나, NoSQL은 스키마를 application이 가지고 있음. application side schema라 볼 수 있음.
NoSQL 종류들
- Key-value : Dynamo, Redis, Voldemort, Riak
- Column Oriented : Cassandra, HBase, Big Table
- Document : MongoDB, Couchbase
- Graph : Neo4j
Big Data와 NoSQL의 관계?
Bigdata 업무를 할때 NoSQL이 필수는 아니다. Bigdata를 정의하는 3V(Vloume, Variety, Velocity)에 따라 Bigdata 활용에는 아주 큰 데이터의 처리, 정형&비정형 데이터가 존재, 실시간&스트리밍 처리가 필요하므로 NoSQL이 더 적합하다고 볼 수 있다.
대량의 데이터를 효과적으로 저장하기 위해 샤딩(Sharding)하거나 Ring 형태의 노드에 멀티 복제하는 방법을 사용한다. Mongodb는 자동샤딩인 반면에 대부분의 RD는 수동 샤딩이다.(Cassandra는 Ring형태의 Gossip 프로토콜을 이요한 다중 복제)
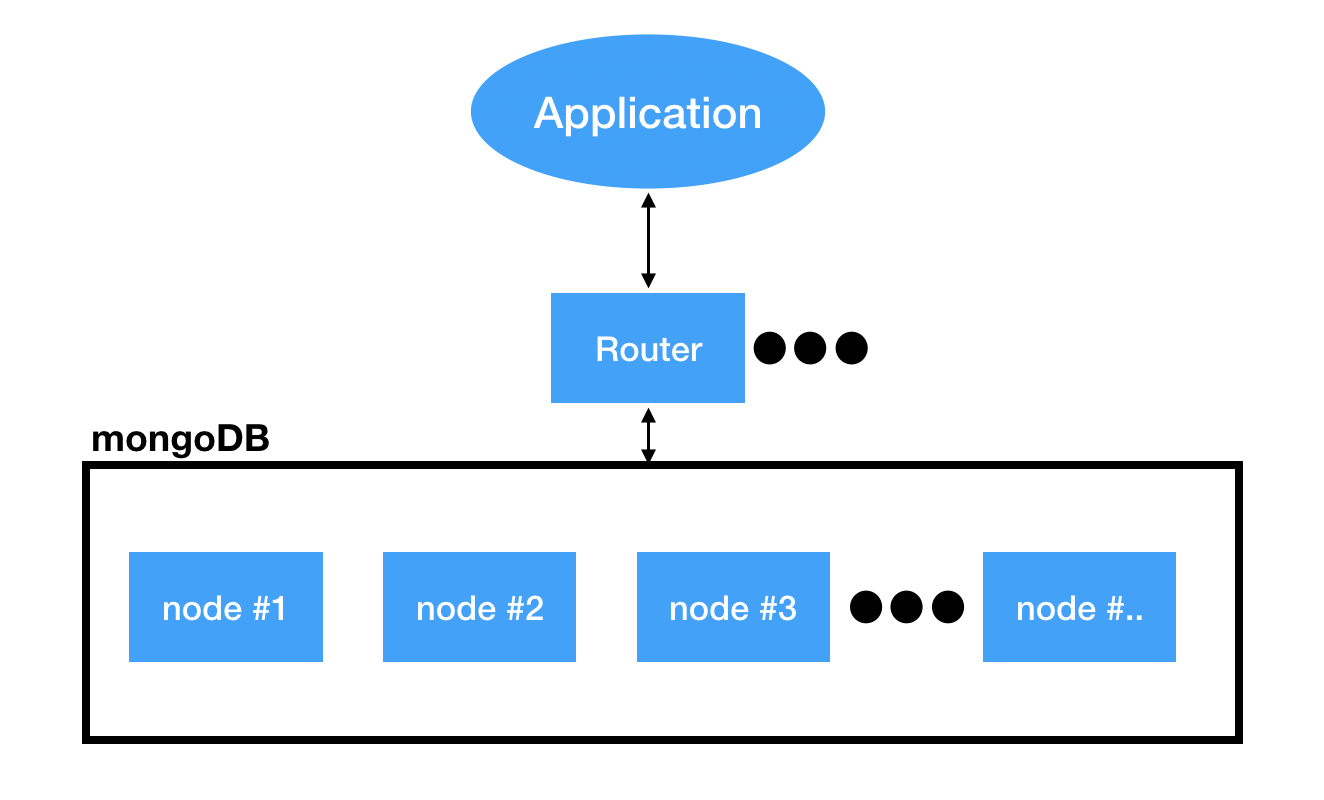
Example) 기존 node 3개 사용중 4개로 scale out할때 기존 3개의 node에 있는 데이터를 4번째 node로 데이터를 적절히 분산시켜야 하는데 이것을 balancing이라고 한다.(mongoDB는 내부에 balancing 알고리즘 존재) 이 때 application은 mongoDB의 router을 참조하여 scale out되더라도 자동 샤딩을 통해 1개의 테이블에 접근하는것 처럼 사용 가능
NoSQL 기본이론
BASE란 Basically Available, Soft state, Eventually consistency를 뜻한다.
- Soft state : 데이터의 사본은 inconsistent 할 수도 있음. 노드의 상태는 내부에 포함된 정보가 아닌 외부에서 전달(전송)된 데이터에 의해 결정됨. 예) replication
- Eventually Consistent : 데이터의 복사본은 더 이상의 업데이트가 없다면, 약간의 지연시간 후에 consistent 하게 됨. 예) DNS
- Basically Available : Fault의 가능성이 있지만, 전체 시스템의 fault가 되지는 않음.
C↑ P↓ A↓ : 일관성(쉽게말하면 복제)을 높이면 성능은 떨어짐. 일관성을 높이면 가용성(HA)는 낮아짐.
C↓ P↑ A↑ : 일관성을 낮추면 성능은 높아지고, 가용성(HA)은 높아진다.
Example) x data를 master, slave에 데이터 복제하는 동안, application이 master에 read를 요청하였으나, slave에 데이터가 쓰이는 동안은 read consistency동안 읽기를 대기한다.(일정시간이 지나면 timeout)

CAP이론에서 Consistency, Availability, Partition Tolerance 세가지 요소가 존재함. 분산시스템에서 동시에 CAP속성을 만족시키는 것은 불가능하다는 것이 Eric Brewer의 이론. RDB는 원래 만들어질때 부터 분산데이터에 생각을 하고 만든 것은 아니며, 분산시스템의 필수적인 성격인 Partition Tolerance 속성을 가지고 있지 않다.
PACELC(Partition Availability Consistency Else Latency Consistency)는 정상 상황과 장애 상황을 나누어 설명하는 개념.
NoSQL vs RDBMS
| 구분 | NoSQL | RDBMS |
| 장단점 | 데이터 무결성, 정합성 보장하지 않음 비정형, 반정형 데이터 처리 |
데이터 무결성 보장(CA) 정규화된(정형) 데이터 처리 확장성 이슈, 분산환경 부적합 |
| 특징 | 약한 consistency schema가 없거나 변경이 용이 |
JOIN ACID |
| use case | 대량 데이터 처리 빠른 성능 요구 |
중요한 트렌젝션처리(금융) 요구되는 경우 |
'빅데이터 > nosql' 카테고리의 다른 글
| NoSQL강의) DynamoDB 개요, 특징 및 설명 (0) | 2019.07.23 |
|---|---|
| NoSQL강의) HBase 개요, 특징, client 설명 + Apache Phoenix (0) | 2019.07.23 |
| NoSQL강의) Column Family Database 개요 및 설명 (0) | 2019.07.22 |
| NoSQL강의) Redis 개요, 기본사용법, command 설명 및 Jedis 예제 (0) | 2019.07.22 |
| NoSQL강의) Key-value Database 개요 및 설명 (0) | 2019.07.22 |
| NoSQL강의) NoSQL 데이터 모델 종류 및 설명 (0) | 2019.07.22 |